
How To Become A Full Stack Data Scientist?
Years of sweating and burning fingers

This is a part of my data science guide series

Some are birds; some are frogs. Some can be birdfrog too!1
Birds love to work at the holistic level, while frogs work at the ground level solving individual problems. People who do both become birdfrog.
Einstein was a bird. Curie was a frog.
(Bird are those who take view from the top. Frog are those who work at the ground level. Frog does not intend frog in the well. Read the reference for more understanding.)
Last year I wrote on how to be impactful without a PhD. This time I want to discuss the path to become a full-stack data scientist. The question of being a full-stack is not just about completing a checklist. It’s a choice between being a generalist or a specialist. The theory of luck states those who hold specific knowledge are rewarded. But an essay2 by Stitchfix argues generalists are much more valuable than specialists in the field of ML.
This guide is written for <5 years experienced engineers looking to become a full-stack. Over here I assume you know the basics of ML, DL and python. So I deliberately skip about it. I have written on them before3.
Why full-stack?
Is a jack of all way more cost-efficient than a few jacks coordinating with each other?
A company making a data science team would choose to hire a full-stack at $2x compared to hiring a data engineer, data scientist, testing and devops at $x + $x + $0.5x + $0.5x = $3x.
Hiring is a tough business, keeping them happy even tougher. One person leaving can bottleneck others. So you create redundancy for each. Hiring individuals is $3x*2, while full-stack is $2x*2 which is a straight saving of $2x = 33%. (The numbers are very rough but I hope you get the point.)
You might question that many people working together will churn out more than a single guy due to more man-hours. But a full stack is usually more experienced and bypasses mistakes made by young engineers. Their past experience helps in attacking the problem in the simplest ways. They see solutions that young engineers can’t. Not to mention they write clean code faster. In this way, they still churn out more in less time.
Unlike regular data scientists, full stacks do not crib what they want to do or what they can do. They show higher ownership and get things done. Seniors love people who take commands, execute, deploy, iterate, document, share and fix bugs. Only a full-stack can do it.
A full-stack is not someone who has done and know things.
A full-stack is someone who is ready to do everything.
Understand the difference.
I am going to skip topics on dashboarding/reporting/business analytics. This doesn’t mean they are not important. In fact, they might be done more than training models. I have no experience in them and will avoid writing on them. I consider them in the domain of Analytics which is descriptive. This post is about being a full-stack DS in the prescriptive domain. (I clarify this because a lot of DS title engineers in America do descriptive while in India it is mostly prescriptive.)
The list I am going to share will be overwhelming for some. Your immediate reaction may be to reject and go back to your usual. I read a similar thing 2 years back and felt insane. My personal suggestion would be to start with topics you find interesting and later diversify into those you find uncomfortable. Once you know everything over here, you will not only be full-stack, but you will be ready to become head of data science.
In my survey, I found full stack DS has a different connotation for everyone. Some think it’s about being good at MLOps while for some it’s about software engineering. In fact, a data scientist means different in America and India. Hence, no matter what I say about this topic, I will end up wrong for someone. I am ok to live with it.
My initial idea of writing this essay was to list the skills needed to become a full-stack. But when I started making the list it felt extremely dull. Instead, I looked at my past and jotted down the skills I learnt every year.
Let’s begin…
Now I present to you how the life of a data scientist evolves with years of experience. Sometimes, you learn skills and get new work while sometimes you get new work and learn the skills.
Please use your judgement in extracting the most useful information for your context.
Year 1 (DS)
Let’s say this is your first job and you are joining as a data scientist.
Python
You will be given the responsibility of writing a few modules mostly in python. Over here your Python skills are of utmost importance. You need to be great at coding which follows SOLID principles, proper OOP along with unit and integration test. Know when to use multiprocessing and multithreading.
Database
As a data scientist, you will often come across databases and I believe that you should know the fundamentals in at least one of SQL or NoSQL databases such as creating, filtering and joining tables/collections. If you are working with a distributed database, you can learn Presto.
A lot of companies give you the task of writing a query in an assignment or interview.
EDA
It goes without saying that you should know the basics of EDA. Spending a lot of time on this might mean you are an analyst and not a data scientist. Again DS means different across the world. So it might also be perfectly fine.
API
You should be able to write clean APIs with logging and error handling. I really enjoy writing in fastapi which also offers API documentation.
Cloud
Most of what we deploy is in the cloud and it becomes imperative to know how to navigate around cloud concepts. Learn how to spin up cloud instances, give resource access, choose right compute instance type and most importantly shut down instances on completion of work. This can look daunting in the beginning but have found AWS docs to be pretty easy to follow. Having good cloud skills is essential part of being full stack. Minimal skills needed in AWS
IAM and security groups
EC2
Lambda
ECR
ECS
API gateway
Cloudwatch and SNS
EMR(for big data)
Containerisation
Docker is quite an essential part of the ML lifecycle. Learn the basics of creating images, container registry, running containers and mounting volumes.
Git
I cannot tell you how many people suck at git when they join. It’s something you can learn in a day but very few actually do. Learn the essentials such as forking, branching, PR, amending, commit message format, rebasing and whatever else you find interesting.
Data engineering
If you are working with a lot of data you have no option but to learn pyspark. In many situations you can spin up a heavy compute instance to get things done. But if your data keeps growing with time you have to design a solution with spark.
Modeling
You should know how to select a model and come up with simpler solutions. Ask the right questions such as what is our business metrics, model metrics and latency requirements. A lot of people miss out on the last one.
Your initial years will be a great experience if you end up in the right place. If you join an organisation that lies about being a truly AI org, you will mostly deal with scraping, scripting, data processing and dashboarding. Some companies have strong hierarchies and they offload non-AI work to juniors. Kindly leave the place asap if the reward of waiting for the right work is not worth it.
Time complexity
Often those who lack a software engineering background create cascading problems. Learn to worry about time complexity especially if you deal with large amounts of data.
Hackathons
As a young data scientist you should spend a lot of time working with different DS problems. Participate in Kaggle(Online) as well as offline(1-3 days event) hackathons. Online hackathons are about the best models while offline hackathons are more around building a product that leverages ML. I had a lot of fun participating in a variety of hackathons.
Work on problems outside of your domain or skillset. This will help you look at problems in a general pattern.
Year 2 (DS)
Year 1 was about getting good at what you are asked to do. Year 2 is about levelling up and go deeper.
Strong modeling
If your work requires complex modeling, it’s best to start reading research papers. Learn the pros/cons of algorithms, layers and architectures of deep learning. Since real-world datasets are not clean-nicely-balanced-with-2-class, you need to dig deep into the effect of class weight, sample weight, label smoothing, hierarchial softmax and adaptive softmax.
Model and data versioning
It’s not necessary to use a framework to do model and data versioning but do have a strategy.
Machine learning lifecycle
Since you have understood that making a model has a series of steps, it’s important to do it right in a clean reproducible manner. Spend time selecting the right tools.
Python design pattern
As you move towards being a senior engineer, learn how to use python design patterns such as decorator, singleton, factory and adapter.
Demo
Ability to share API as a Streamlit demo is quite helpful for debugging and presentation. In large companies the presentation is done by the analyst or product manager. You have to do it yourself in startups. Making demos is fun and a good exposure to UI/UX as well.
CI/CD
I have become a fan of GitHub actions. If you are into the ecosystem, learn a few workflows. Common use cases include:
Run tests on pull requests
Deploying packages
Push to container registry
Linting with black
Labelling PR
Close stale issues
You can also learn Jenkins if needed. Github actions are powerful enough to test transformer models.
Writing tests
I neglected writing tests for a long time and now I regret it. If you want to do development the right way, add unit/integration as soon as you are done with modules. Make it part of your development and not a separate thing. Goku wrote an amazing piece recently.
Setup code-coverage report GitHub action to monitor code quality.
Reading research papers
This is a good time for you to start reading papers. Instead of reading the paper of the moment, you can start with classical papers to understand the basics of ML evolution. To this date, I find word2vec useful and is often asked in interviews to check if you know the right things.
Many engineers worry of ML papers being filled with daunting mathematical equations. This is not true at all. If you enjoy reading blogs, consider papers to be even more fun.
How to read papers the right way is another topic in itself but try advice by Yannic and Nirant. Some other tools I find useful
A lot of people face trouble in selecting the papers to read. Rather than going with any paper you see in updates, read something which helps you at work or fits your future interests. I particularly enjoy those which come in the applied AI domain such as the YouTube recommendation papers.
Make notes, write blogs and share insightful nuggets. I have read many papers but I only remember a few which I converted to blogs or read many times.
You actually don’t need to read a lot of papers. You will be way above average even if you read 1 every week. You can read more if you plan to be a researcher. I once met a guy who read 1 paper every day while commuting to office.
Year 3 (becoming senior DS)
Now that you have become good at the basics of ML workflow, you can start getting ready for lead roles.
System design
Learn to think at a system level. Design high performance and high availability systems. This requires you to understand distributed systems concepts such as load balancing, autoscaling, caching, sharding and rate-limiting.
Read engineering blogs of companies to know real-world ML systems. Practise designing applications to get a hang of it.
ML system design
There is more to system design in ML than just software. Deploying reliable ML systems is tricky when there can be self-feedback loops that deteriorate the system. You should be able to break design into
Business and technical requirements
Online and offline metric
Feature engineering
Modeling -> Training -> Inferencing
Cost estimates
Optimisations
Logging and A/B testing
Watch Stanford ML design series to learn from the masters. This will just get you started and you will have to build a few systems to get the true taste of troubles.
Costing estimates
ML training and inference can be compute heavy. Learn to do cost estimates as ML is often used for automation for cost reduction. The project fails if the automation cost is more than manual. Test different models on different compute instances to know their latencies. Learn to correlate compute with number of parameter to calculate ballpark figures.
The dynamics of batch, live and serverless are different. Leverage different cloud products for cost saving. Serverless is still not well adopted in ML enough though it should.
Data annotation
Unsupervised often works but you cannot improve it. To get better results you have to improve your models, often with transfer learning. If you do not have log data due to young product or missing log infra, you have to create training data manually.
This skill doesn’t have any specific need per se. You have to set up annotation task via tool like Prodigy or as simple as Google sheet. For complex scenarios, you can also build your inhouse tool. Something to be cognizant about is to know all datasets are biased and will lead to biased models too. Have datasheets for datasets.
Container orchestration
Container orchestration becomes essential when you are working with large varying loads. Learning Kubernetes might get on your nerves but understand the basics. If you feel uncomfortable, at least get a hang of ECS/EKS in AWS.
Mentoring
At this stage, you might be working with others who are new to ML. Learn the art of teaching and giving feedback. Organise knowledge sharing sessions on work-related topics to keep everyone updated. Encourage discussions on new topics and plan for future use cases.
Code review
Code review is very critical for maintaining code quality. Establish code review guidelines with rigorous manual and automated checks. Be respectful and give constructive feedback.
Year 4 & 5 (becoming full-stack)
Now you are at a point where you are handling complete projects. You are responsible for end-2-end execution. It’s time for you to push the limits of your engineering design.
Niche
At this stage, you should look back and see if you enjoyed working on particular systems or domains.
Problems
Fraud analytics
Search
Recommendation
Time-series predictions
Object detection
Speech to text
Domains
Finance
Ecommerce
Social media
Being great at ML is going to be hard but can be made easier if you choose to focus on a particular set of problems. It’s ok if you haven’t found your thing.
Supervised Vs Unsupervised
May I say supervised learning is not as hard as it used to be unless you choose to modify the neural architecture?
Most DS obsess about supervised learning. But if you want to work for startups, develop a mentality of unsupervised learning. I often see people trying to train models with less data, failing and then trying unsupervised learning. Being open to unsupervised learning will help you deliver decent solutions quickly - what matters to startups and early ML teams for business proof.
ML design patterns
At work, you might be solving a particular use case. This might limit the things you get to learn. Over time this can become a bottleneck for future roles or just make you myopic. Read and discuss beyond these use-cases.
Study how to deploy the model for batch inference, API, serverless, edge and over streaming data. Knowing the pros and cons of different ways of deployment will not only save trouble but bring immense savings to your company.
Cloud architecting
Once you know the basics of system design, you can use them to design your own ML solution in cloud. This will still require you to know the cloud-specific components and their functionalities. You can read some of the AWS solutions to get a hang of it.
Code as infrastructure
While working with the cloud, you will frequently come across creation of many resources manually. To make a true end2end cloud solution, you need to learn code-as-infrastructure.
Experiment design
Since you will be accountable for pushing models and their subsequent better versions, it will be onto you to quantify technical and business metric improvement. Learn how to select the right candidates for experiments, train and deploy them. This brings us to monitoring.
Monitoring
You require monitoring for A/B testing or detecting model drift or concept drift or anomalies. Understand what is to be monitored with what frequency and the definition of anomaly.
Build or own
Often you will come across tradeoffs between using external ML APIs versus building your own models. This will require you to evaluate your own strengths, project timelines and competitive advantage. The earlier you know the tradeoffs, the faster you will be able to execute projects and create value.
Do not get fixated on building inhouse capability for everything. This happens often due to over-excited data scientists curious to write that magical line model.fit. One thing which helped me understand tradeoffs is working at startups. You can leverage ML APIs and managed solutions instead of open-source.
Year 6 onwards (life after full-stack)
If you have been able to get projects executed well without much help from the manager, you are the manager.
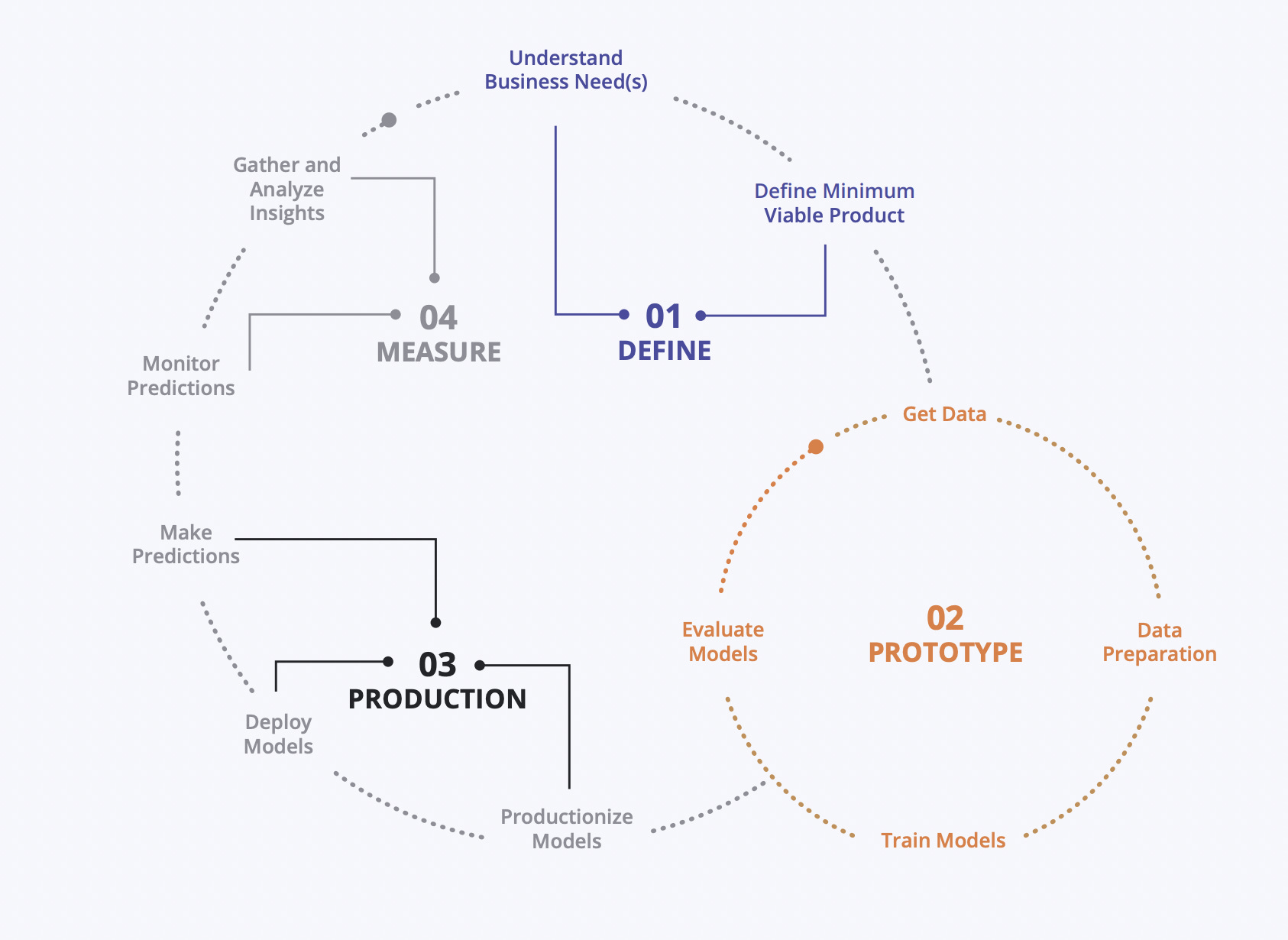
ML platform
The first five years were about trying things hands-on. Now it’s time for you to set the vision of execution. At this stage, you can contribute or plan modeling infrastructure of the organisation. Watch these talks by Uber and Lyft to get an idea. Build cloud, hardware and framework agnostic internal framework to help DS churn out more value.
Understanding and designing the data infrastructure for OLAP and OLTP will become essential. Worrying about the data quality, monitoring and improving can also become part of your role.
As your teams deploy many models, having a common infra for monitoring is essential. Deciding the model and business metrics for every use case is needed to build confidence in models and improve them further.
Architecting solutions
As data scientists, we think monolithic. Broaden your thinking by studying micro-service architectures. Analyse pub-sub, service-oriented and event-driven architectures.
Read engineering blogs to seed your knowledge. You won’t understand more than half in the beginning but it will open up ideas to you.
If you want to design high performance distributed systems, learn about socket programming and message queues. Understand distributed databases, distributed logging and, distributed training.
Management
You will be promoted to a managerial position(if you wish to) and, your priorities will change. Now you will shift your focus to hiring, team building, leveraging skills of people and project planning. You can start to learn how to pitch clients, do a competitor analysis and crack sales. Expand your technical strategy thinking with 1 2 3 4 5 6 7 8 9.
Architecting products
All your ML career you will be working with the backend. I think this becomes a huge bottleneck as a value creator. To have full ownership/vision, you have to get into understanding front-end development. I have no idea about making front-end but want to pursue someday for sure.
You can start acting like a product manager, create product roadmap and execute to fruition. There is no dearth of work you can do lol!
Slowly and gradually, you will be the CTO.
Will it take 5 years for everyone?
Definitely not!
As you can see, a lot of full-stack skills are about software engineering. If you come with real software experience, you have an advantage.

You are being impatient if 5 year sounds long to you. The ML landscape is complex and will be even more in the future. The number of skills you are supposed to know is staggering. If this shatters any notion you had, good for you. Now you can have the right expectations.

A lot of things will remain same over the years such as writing code but the degree of ownership will keep increasing. You start with using other’s code as reference but then start making references for others. In the end, you design and build internal frameworks for all the teams in your company.
To conclude
I will stop here and come back to the original question. In 5 years you can either do a PhD to become a specialist or work on a variety of problems to become a generalist full-stack data scientist. Sit back and ponder for a while. Do you want to be a frog or a bird?
In these years, some things will make you extremely uncomfortable. You will often be in situations where you have to chose between writing clean code vs doing ML experiments. The decision won’t be in your hands. The need of project and team will decide your action. This happened quite a time with me and I realised that what makes me comfortable is not necessarily good for me down the line. Some of the most useful learnings came from things I absolutely neglected/hated/underrated. So keep yourself open to everything. This happens quite naturally/forcibly in startups.
Since 5 years is a long time, how will you optimise them if you choose to be a bird? If you really enjoy working at your place, you can continue till 5 years. But if you aren’t, you should leave asap. You will get a wide understanding in these years if you work at 2 different domains at 2-3 companies of different sizes one of which should be an early-stage startup. The benefits of environment eliminates the need for passion.
At the end, I would like to add that writing this post doesn’t mean I know it all. Consider this my own wish list! I will add/finetune the list as I learn along. And, it is not necessary to learn system design in your second year of work. You can start early as well.
Since this post was about introducing the path to becoming a full stack, I haven’t talked about many things in detail. Do let me know what should I probe in detail in my next posts!
Have a good run! Try uncomfortable things. But leave if it’s not fun.
Ending on this beautiful excerpt
Generalist roles provide all the things that drive job satisfaction: autonomy, mastery, and purpose.
Autonomy in that they are not dependent on someone else for success. Mastery in that they know the business capability from end-to-end. And, purpose in that they have a direct connection to the impact on the business they’re making.
If we succeed in getting people to be passionate about their work and making a big impact on the company, then the rest falls into place naturally.


Special thanks to Nirant, Amit, Ramsri, Aditya and Peter for their feedback and suggestions :)
Come join Maxpool - A Data Science community to discuss real ML problems!
Connect with me on Medium, Twitter & LinkedIn.
https://3quarksdaily.com/3quarksdaily/2020/11/birds-and-frogs-in-physics.html
https://multithreaded.stitchfix.com/blog/2019/03/11/FullStackDS-Generalists
Amazing post!
Maxpool slack site is not working :
Any latest update regarding that