
101 For Serving ML Models
Learn to write robust APIs
Learn to write robust APIs

Me at Spiti Valley in Himachal Pradesh
→ ML in production series
My love for understanding production engineering and system design has been growing steadily.
Earlier I have written on the steps required to put a model to production but I haven't touched details of making an ML server.
Let's assume that you have finalised your supervised/unsupervised approach and now you have to build API for inference.
In this article, I will cover the basics of ML model serving and how to do a CPU/GPU deployment.
CPU deployment 🚀
Now we will look at how to write APIs for doing a CPU deployment as they are very common in practise when the load is not high.
We will cover
Task Queues
Caching concepts
Worker concepts
Framework combo → Fastapi + uvicorn + huey + redis
→ Task Queues

Why queue?
Servers like flask and uvicorn do not maintain a queue of API calls and things are concurrent by default. This is great because it can help you with better utilisation of the server. But if you have delete and update APIs, you might be changing the state of the server.
This can cause havoc when concurrent calls are trying to access the same objects in memory which are getting altered and accessed at the same time.
Hence you need a queuing mechanism when concurrency is a problem.
The preferred method to deal with this is to create tasks and send them to a queue maintained by a worker which executes them sequentially.
The caveat is it can make our response slower if the queue gets long. You can consider making task async and return fixed response if the response to the call is a fixed one like “update of x will happen”.
General Queing Theory
Producers — The code that pushes tasks to the queue.
Exchangers — Decides which queue a message should be pushed into.
Direct (Send a message to the queue with respective table)
Topic (Send a message to the queue that matches a specific routing pattern)
Fan out (Send a message to all queues)
Queues — Queues are what we have been discussing so far. It has a list of tasks for the workers/consumers.
Consumers — Consumers (Worker), also called as workers, are responsible for the actual execution of tasks. At any point of time, workers can be configured to work on a specific queue. (RabbitMQ/Redis does not have it’s own worker, hence it depends on task workers like Celery.)

Huey task queue
Many people use Celery for task queue but it requires a good understanding to use it properly and has many features you might not require. I found huey as a clean minimal alternative to Celery.
RQ vs. Celery vs. huey
Celery supports RabbitMQ, Redis and Amazon SQS. RQ is built only to work with Redis. huey works with Redis and sqlite.
Celery and huey support scheduled jobs.
Celery supports subtasks. RQ and huey doesn’t.
RQ and huey support priority queues. In celery the only way to achieve this is by routing those tasks to a different server.
RQ and huey only work with python, Celery works with python, go and node too.
Type of queues
Write all your tasks in core.py
# In core.pyfrom huey import RedisHuey, PriorityRedisHuey, RedisExpireHueyhuey = RedisHuey('worker') #simple FIFO queuehuey = PriorityRedisHuey('worker') #queue with task prioritieshuey = RedisExpireHuey('worker') #queue which persists response in redis for only some time to save spaceDifferent tasks
Task with a priority of 10 (10 gets more priority than 1)
@huey.task(priority=10, retries=2, retry_delay=1)def predict_task(name:str):
...Periodic tasks such as fetching data or updating data
@huey.periodic_task(crontab(minute='0', hour='*/3'), priority=10)
def some_periodic_task():
...huey task worker
Start the worker which logs errors
huey_consumer.py core.huey --logfile=logs/huey.log -q→ Framework
Why Fastapi?
Fastest — Write the API in fastapi because its the fastest for I/O bound as per this and the reason is explained here.
Documentation — Writing API in fastapi gives us free documentation and test endpoints → autogenerated and updated by fastapi as we change the code
Validation — Supports datatype validation by pydantic
Workers — Deploy the API using uvicorn for more than 1 worker
Supports async calls
Background tasks
→ Swagger API docs
This is autogenerated by fastapi at http:url/docs

Async task
For some things, you don’t want the result immediately. You can make such tasks asynchronous.
from fastapi import FastAPIimport coreapp = FastAPI()@app.get("/api/v1/predict/{name}")
def predict(name:str):
core.predict_task(name) #This is asynchornous
return f"predict will be executed with {name}"Synchronous task
For some things, you want the result immediately. You can make such tasks synchronous.
import core@app.get("/api/v1/predict/{name}")
def predict(name:str):
return core.predict_task(name)(blocking=True) # synchornous→ Caching concepts
Cache size → Optimised as per need, server compute and storage
Cache eviction policy → Since we cannot cache everything, we need to remove less used items.
TTL cache
Keeps the cache till time specified after last usage.
LRU cache
Least recently used — FIFO queue. This makes sure to remove old items from the cache queue
LFU cache
Least frequently used — tracks stats of which items are asked more and keeps the most used once.
Most people use LRU in practice because it guarantees both cache size and recency.
from huey import RedisHuey, PriorityRedisHuey, RedisExpireHuey
from cachetools import LRUCache, cachedhuey = RedisHuey('worker')cache = LRUCache(maxsize=10000)@huey.task(priority=10, retries=2, retry_delay=1)
@cached(cache)
def predict_task(name:str):
...→ Worker concepts
If you have a multicore machine, you can start more than one workers to increase the throughput of the server. Every worker acts like another server in itself.
Max number of workers is limited by RAM and cores.
You cannot start workers more than RAM/model_size and you also shouldn’t start workers more than 2*cores + 1.
→ Logging
Last but not the least.
May I say logging is under-appreciated?
Uvicorn supports server logs out-of-the-box.
Just save the below config at config/logger.config.
This will keep individual log files of last 7 days which you can check for debugging.
→ Start the server
mkdir logsuvicorn main:app --workers 1 --host 0.0.0.0 --port 8000 --log-config config/logger.configGPU deployment 🔥
Now we will look at how to take care of batching so that we can use the power of GPUs with batches.
Framework combo1 → Fastapi + uvicorn + huey
Framework combo2 → Tensorflow serving
The reason we use GPUs is to get the benefit of fast matrix multiplications using CUDA in GPUs. To get the real advantage we need to process the requests in batches.
→ Batching concepts
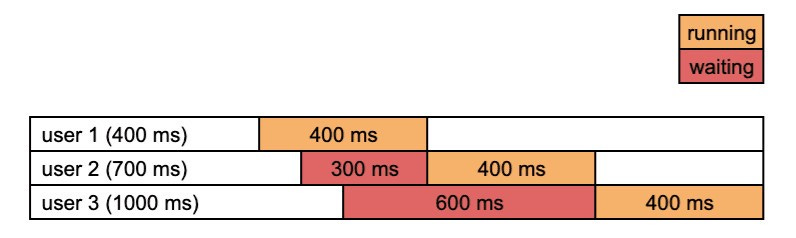
Without batch
The image shows how requests are processed without any batch.
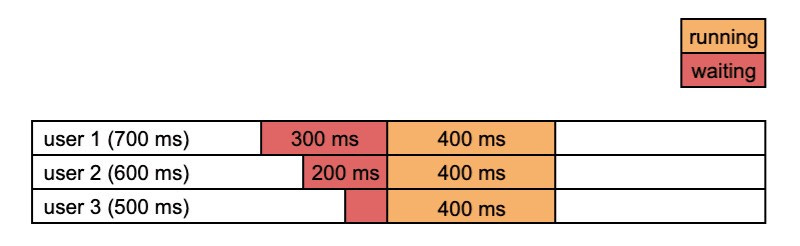
With batch
The below image shows how batching works. The requests are not processed immediately but rather in batches after a fixed time delay.
Batching becomes possible only when you do a GPU deployment and GPU deployments are way costlier compared to CPU.
You do a GPU deployment only when you have enough throughput to justify cost or latency.
From the below image we can see that after a particular amount of throughput, batching gives superior performance compared to no batching.
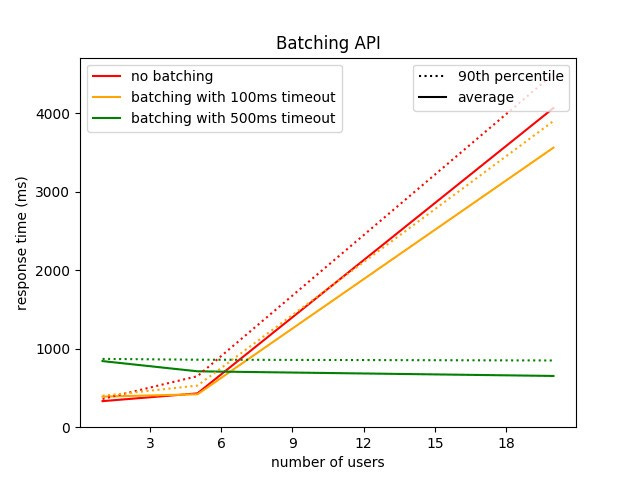
Advanced batching concepts
There are also other batching concepts which are used in frameworks like clipper as mentioned in this article.
Adaptive batching works to find the right size for the given batch. One way clipper does this is by using “Additive increase multiplicative decrease” (AIMD) policy.
That is clipper keeps on increasing batch size in constant increments while SLOs are being met. As soon as latency SLO misses, the batch size decreases multiplicatively. This strategy is simple and works very effectively and is the default that clipper provides. Another approach that the authors explored was to use a quantile regression in the 99 the percentile of tail latencies and set the max batch size accordingly. This performs similarly to AIMD and is not as simple to implement due to computational complexity associated with quantile regressions.
Delayed batching is useful when the workload is bursty or moderate. In such cases, the optimal batch size chose for the given framework may not be reached. In such cases, batches can be delayed by a few milliseconds so as to accumulate more queries.
Custom batching implementation
→ Logging ✍️
Logging is boring and that's why we neglect it. 😞
This is a module for custom logging which you can use at various points in the code.
→ Monitoring 📊
Keep an API health check monitor for alerting when the service goes down. This is neglected a lot in practice.
→ HTTP status codes
As data scientists, we often lack common knowledge and its good to remember these error codes
400 Bad Request — This means that client-side input fails validation.
401 Unauthorized — This means the user isn’t not authorized to access a resource. It usually returns when the user isn’t authenticated.
403 Forbidden — This means the user is authenticated, but it’s not allowed to access a resource.
404 Not Found — This indicates that a resource is not found.
500 Internal server error — This is a generic server error. It probably shouldn’t be thrown explicitly.
502 Bad Gateway — This indicates an invalid response from an upstream server.
503 Service Unavailable — This indicates that something unexpected happened on server side (It can be anything like server overload, some parts of the system failed, etc.).
→ Testing API
Testing API is extremely critical because models can be heavy and they make the API CPU bounded.
Work with your App, Web or business team to estimate API usage. You need to do 4 kinds of testing
Functional testing (ex. expected output for given input)
Statistical testing (ex. test the API on 1000 unseen requests and the distribution of predicted class should match train distribution)
Error handling (ex. data type validation in request)
Load testing (n simultaneous users calling x times/minute)
Note: Do not deploy APIs to production without minimal testing 🔥
Conclusion
In this article, we covered how to write sync/async APIs, task queue, batching mechanism and testing. I hope you found the article helpful.
Another way to take care of all this is through frameworks like Tensorflow serving or cortex which I will be covering in my next article. 😃
Modern NLP
All the latest techniques in NLP — Natural Language Processing