
Guide To Get In Data Science — Part-1
The world’s most valuable resource is no longer oil, but data.

The world’s most valuable resource is no longer oil, but data.
— The economist
People with almost all backgrounds — IT, mechanical, electrical, electronics, energy, chemical and civil, with people from B.Tech, M.Tech, B.Sc, M.Sc and even Ph.D, varying with no experience to 5 years of experience in my own circle and outside — asked me the same question — Should I get into data science? So hereby I will try my best to share how you can make it, with our knowledge on economics, psychology and study hacks.
Once a doctor asked me for guidance on LinkedIn!
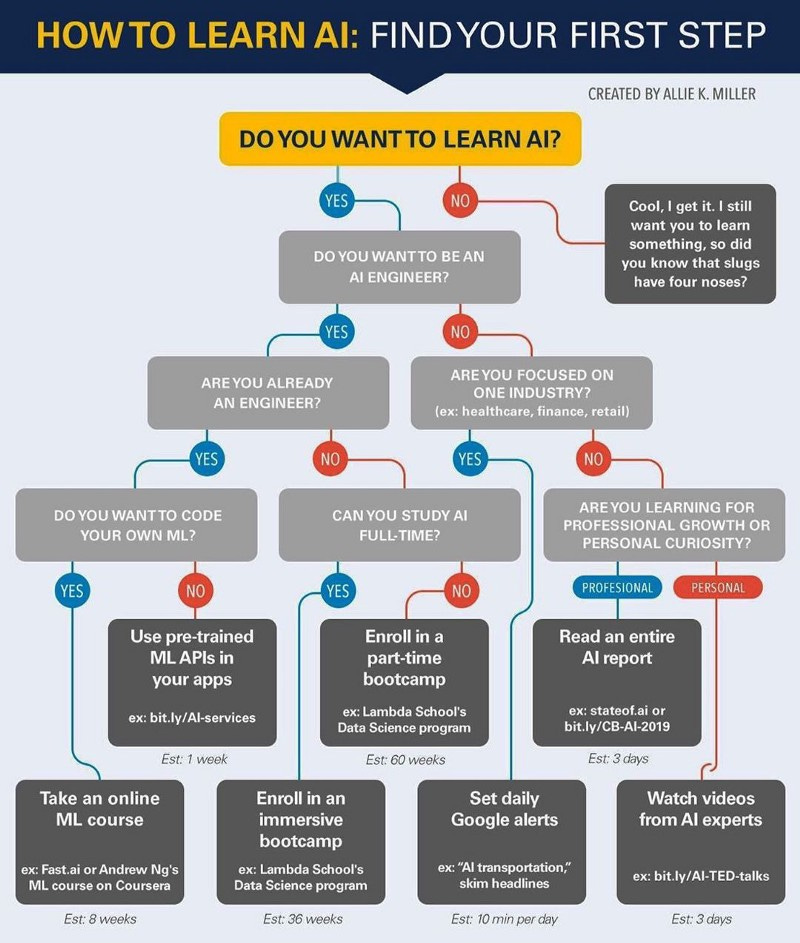
Note: This article is about general guidance to get in data science. Check this article if you are looking for courses.
If you are looking for courses, check Guide To Get In Data Science — Part-2.
If you are looking for guidance on NLP
Psychology
To be frank, getting into data science is a game of capturing your fears. In the beginning it will get overwhelming with tons of acronyms and jargons but you will have to get used to it. And if you have been pretty fearful of equations back then in college, either it’s time to break your fears or forget your dreams of getting in.
My initial days were filled with technical doubts as well as self doubts. The learning curve was steep, and confusion just kept on rising. After making countless notes and revising them almost 3 times, I was able to absorb material on its grand scale.
Study Hacks
On journeys like this, it’s always good to have a companion. I found people through Facebook, Whatsapp and Telegram groups and learnt immensely by pairing up with them on projects. Work on the same project, push code to Github and discuss. This will keep you rolling and expand your approaches. There can be so many ways to solve the same problems that you will be surprised. A good data scientist is essentially someone who has made enough mistakes to know what will not work. So pair up with people and work on different ideas. Google and find how people worked on a Kaggle problem and try to understand it. In case you have no ideas initially, just download data and available code from Kaggle and rewrite it line by line. My first clustering project happened exactly like this. I just rewrote existing stuff and tried to make sense of each line and the maths behind it. Later I started writing my own with help from StackOverflow. Now, if I am working on a problem already tackled before, I know what to do without any guidance or tutorial. It’s a god damn journey. Also, you will hardly remember the syntax unless you are doing the same thing every day. So don’t worry about it. Just open the documentation or tutorial and start writing.
Get in the ecosystem
Try to invest time in your LinkedIn profile from the beginning. It serves 2 purposes. Not only you will start networking with people in the industry but you will also get to know DS projects and recent advancements in the field. DS is evolving so quickly that you need some source of updates and there comes LinkedIn. This Facebook group is also very active and you can use it to find people of similar interests.
With time, you will realise how less you remember of things you read. Hence, invest time in making notes. I used to pause videos of Andrew NG and make notes. It took almost thrice the time than watching videos but I ended up learning more — which is required in the beginning.
Try to answer doubts of others even though you might not be an expert. This will lead to a deeper clarity on topics. Some of these can also end up being your interview questions.
Courses
There are a lot of courses and many approach the same topics in different ways. Initially, I was of the opinion that you should do only one course and that means you should find out the best course and do it. I selected Andrew’s course on Coursera. Later when I was placed and had time, I checked out a course on Udacity. I came to know that it is a more practical course on the pros and cons of algos and this was not discussed much in Andrew’s course. So it seems, different experts have different insights to share.
Hence, if you want to start a course, just do it. All of them are available for free. Stop the course if you feel uncomfortable with the style and content. I agree that Andrew’s course is a bit dense and requires you to watch it more than once. But that’s how you learn to not give up and learn what is required.
If it was easy to do data science, everyone would have been doing it, demand would have been less than supply and people would not have been paid so high. So start with any course and don’t give up easily.
Time
Many people ask how much time will it take to prepare and get a job. Since time is a function of your current knowledge and grasping ability, I would rather define it in terms of projects. Doing all the basic courses and around 8 supervised and 2 unsupervised projects can easily take 4–6 months of dedicated(10 h/day) effort. If you are doing it part-time, you can easily take 8–12 months. (Including time of finding companies and interviewing with them.)
Economics
If you are a non-IT professional, it is going to take a hell lot of effort to learn it and you don’t wont to be disappointed!
If you are an IT professional, you are in an advantageous position. In DS interviews we definitely give importance to people who have worked in IT as we don’t have to teach them all the nitty-gritty of how IT works. No matter how fancy DS looks, at the basic level it is still IT. We want people to know the IT stuff — database working, querying, ETL, testing, deployment and clean coding.
People with a history of IT have exposure to this and adds a boost to the resume. The only thing they need to take care is all the data science — which seems much more manageable to them compared to non-IT people.
Since their learning curve can be faster and they can leverage the past experience to get a better offer, their risk of exploring this direction is definitely less.
Interviews
Ideally, once you have gone through the basics, you should start interviewing with companies to get a sense of the structure of interview and get comfortable failing at it. You can find some good companies hiring on platforms such as CutShort.
Remember that these interviews can get excruciatingly tough. My experience tells me that the better the company, the tougher the interview. The richness of interview almost acts as a proxy of the strength of the team interviewing you. So if you are doing a very easy interview, chances are that you are going to get into some low-quality excel or scraping stuff.
If you want to get into a good job, you should be great at the nuances of navigating an interview. Once you get into this process of interviewing, some of them will give you coding assignments. Here, it’s important for you to write your own code and review it with the aim of finding flaws in it. I cannot tell you how much I have screwed up in these assignments. I made projects with technical flaws and poor coding practices. But with each failure I found ways to do it better. I look back at those scripts some time and realise how far I have come.
One thing to note here is — Don’t get it done by your friends. You can consult them if you want but get into the habit of cracking problems on your own. It is easier said than done but it will develop a character in you.
The day of cracking your first job in data science will be etched forever in your memory.
Things to know to increase your chances of cracking interviews.
Statistics — A lot of companies ask on Bayes theorem and Normal distribution
Machine/Deep learning basics — Algorithm pros/cons and working
Strong coding skills — Python + Competitive coding
Database — Minimum required is SQL skills. Good to know both SQL and NoSQL databases.
Cloud computing — A huge add-on but not an absolute necessity. Learn basics of AWS(Amazon Web Services)
Github — Displaying good work on Github shows confidence and enthusiasm — what best companies look for
Blog — Blogging leads to self-clarity on your topics of interests. Also, since I learnt a lot by reading blogs of others, I always like sharing my own learnings.
How I judge companies
The tougher the interview, the better the team, work and pay.
I check out the profile of team members and leaders on LinkedIn. I check out their history of work and current work descriptions. Sometimes people write vague descriptions or say I do scraping — This is a strong indicator for me to stay away from the company.
Data science is god damn huge. If you want to learn quickly, join the team where smart people are. Sometimes they are startups and sometimes they are MNCs. The question of startups Vs MNCs is a debate worth another blog post. There are practices to learn from both of them. Startups have agility and MNCs have resources.
Try to get into a company which is a market leader in at least one thing and has research-oriented mindset. It shouldn’t be a company which is doing data science for cost reduction but does it because it’s their bread and butter. Such companies are rare though.
At the end of the interview, I ask age of the team, its size and the average experience of team members. I don’t hate startups or small teams but I just like to know the metrics. I also probe on what problems they are working on currently but most of them will not answer due to privacy.
I have LinkedIn premium — so I check out the growth of hiring of the company in last 3 months, 6 months and 1 year. I specially do this for small companies and startups. Growth of a team is directly related to the health of organisation. This is good to have but not a necessary criteria.
Check out reviews on Glassdoor.com for the company. Be sure to confirm if the work environment is healthy otherwise just cancel the process. If things look well, be ready with what kind of CTC they might roll out. You can also check the numbers in advance to see if they fit in your range. You can also ask them directly what’s their range to avoid wasting time.
You can find some great questions to ask your interviewer over here.
Yes, all this is one long story. Just give your best. Earn it.
Check out Part 2 for courses on data science.
Guide To Get In Data Science — Part-2
Things to know to get into Data Science
This was originally published at Modern NLP.