
Zero To One For NLP
All the best NLP resources out there


Come join Maxpool - A Data Science community to discuss real ML problems
NLP has grown into a field of wide applications ranging from chatbots to news generation. I started my journey into NLP with standard courses but a majority of my practical learnings came from personal blogs of researchers.
This metablog is a collection of my favourite blogs and courses I go through every once in a while to refresh myself.
Basics
fastai
Embeddings
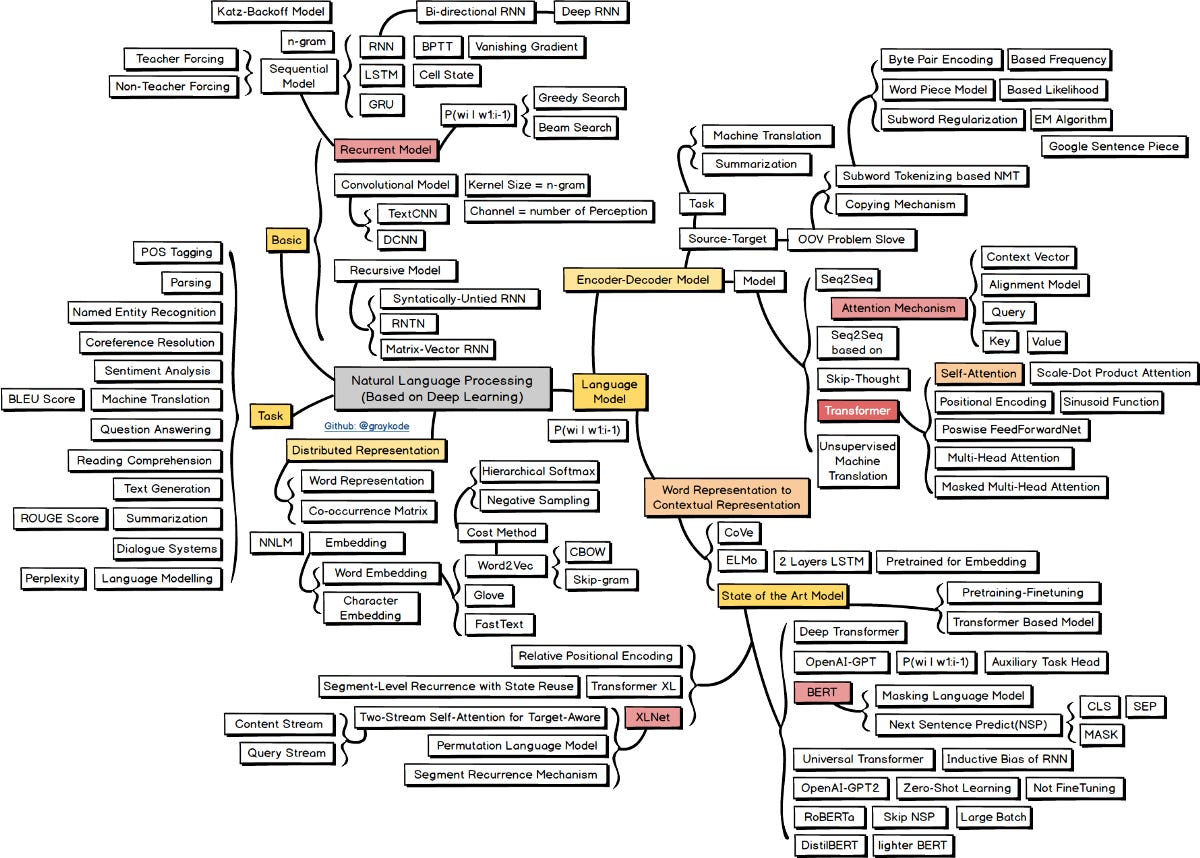
https://github.com/graykode/nlp-roadmap
Attention
Language models
GPT
Embeddings summary by Lilian Weng
Transfer learning
ULMFiT (Universal Language Model For Fine Tuning)
Transfer learning
PyTorch
NN concepts
Normalisation
4 Sequence Encoding Blocks You Must Know Besides RNN/LSTM
Conversational AI
Neural Approaches review paper
What makes a good conversation?
Denny’s
Rasa
Huggingface
Putting ML to production
Airbnb
Uber
Extra tips
Interview
Libraries
Semantic search
Random
Hackathons
AutoML
Papers and code
This was originally published at Modern NLP.
Come join Maxpool - A Data Science community to discuss real ML problems!