
LLM Chronicles #1: Will LLMs Make NLP Scientists Jobless?
"In retrospect, I wish I had known more about the hazards and difficulties of working in AI." -- NLP scientist


Let’s think step by step.
Once upon a time, in a small village, the people would gather every Sunday at the church to pray and worship. However, they did not have clocks to tell them the time of day. To overcome this challenge they would observe the position of the sun, and know whether it was time for morning prayer or not. They would also use the sounds of nature, such as the chirping of birds, to confirm the time.
In the evening, the villagers would look up at the sky and observe the constellations to estimate the time of night. The ringing of church bells was used to signal the start and end of prayer times.
With the invention of the mechanical clock, everything changed. Those who made a living by telling time for prayer at church found themselves out of a job. This phenomenon is not unique to the invention of clocks.
However, while jobs may be lost, people tend to find new opportunities to support themselves. This cycle of displacement and creation is a natural result of technological progress, and it underscores the importance of being adaptable and open to change in our modern world.
Now let’s discuss LLMs. For everyone’s context, ChatGPT is an LLM by OpenAI which can do conversations.
The recent advancements in LLMs have significantly changed the NLP landscape. Tasks once considered difficult or impossible, such as summarization, are now achievable through LLMs. But the question remains - has it solved it all?
A study by researchers found that about 80% of US workers could have at least 10% of their work tasks impacted by GPTs, while 19% may see 50% of their tasks affected.
Over the last 2 years, I have worked with many applications which would/ would not require using LLMs such as semantic search, query suggestion, classification, few shot classification and question answering.
Let me share how it affects the workflow of a data scientist.
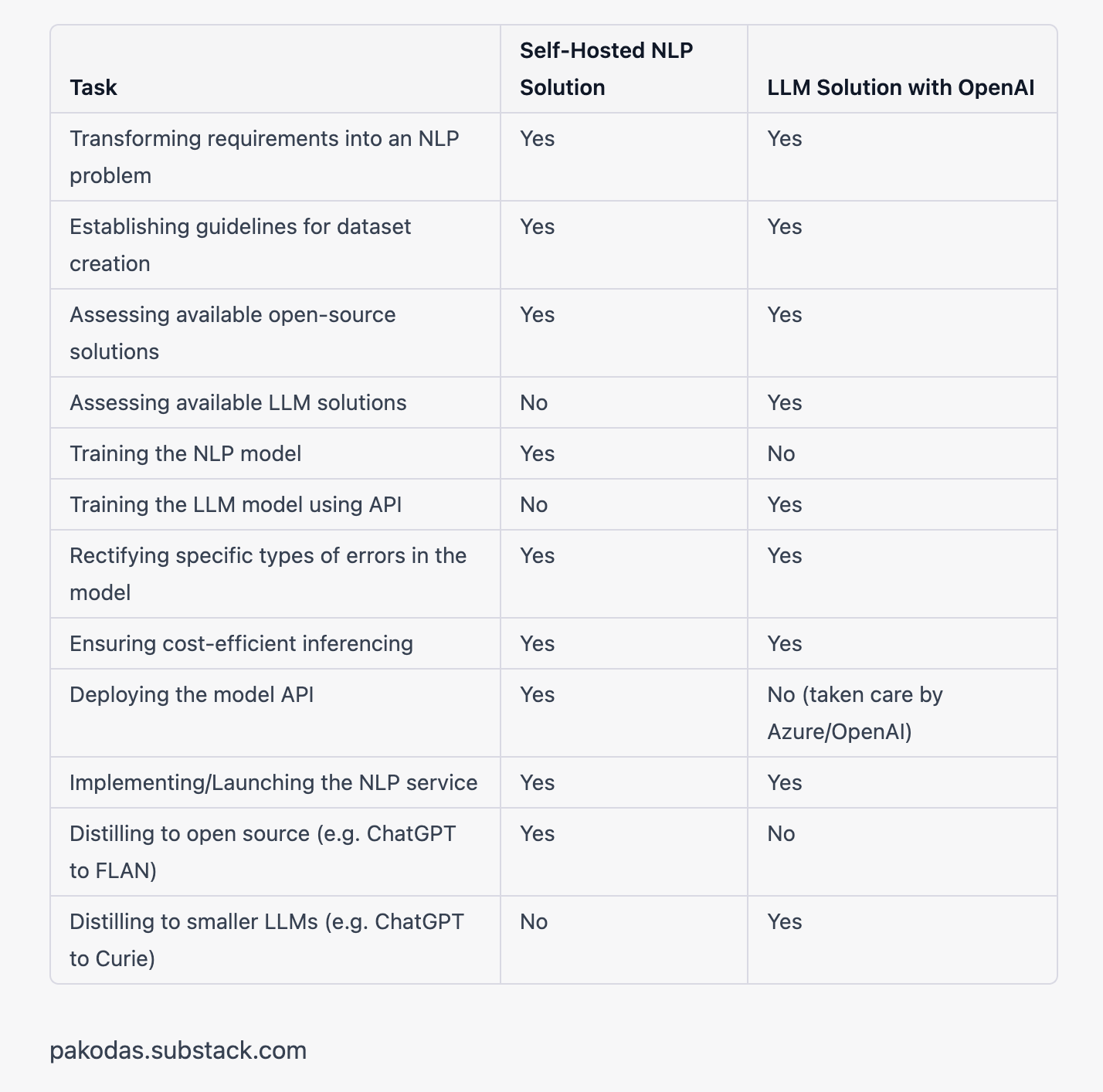
As you see there are many common things which require a full-stack NLP data scientist. This job is not going away. There is no automation for it. Every company is unique. So are the problems.
Now let’s look at the differences.
Training and distilling for self-hosted make it an NLP research job, while deployment is a full-stack job.
Training and distilling LLM makes it a full-stack job.
From this, we can conclude, full stacks are well-positioned to generate immense value for companies in any case.
Check out this post for more info on what it means to be a full-stack data scientist.

How should NLP engineers deliver more value?
The advent of LLM has presented novel opportunities for applied ML problems. Below, I have listed what I perceive to be the most significant ones.
Understand where and when to use LLM
When it comes to where, it's crucial to understand that not all tasks can be executed efficiently using LLMs. For instance, GPT is not ideal for NLI, so prompt engineering or training for such tasks might be futile.
As for when to use LLMs, companies with fast iteration loops are more likely to succeed in leveraging LLMs for quick validations compared to those who don't. This is particularly important for startups. LLMs are well-suited for tasks that require annotated data and have time constraints.
Look at this chart in order to understand how to select an approach when data drift and complexity is known.

Prompt engineering
Stay updated with the research in prompting and new LLM releases to be effective at writing instructions, selecting samples for few-shot, batching, breaking the task into steps & balancing quality/cost tradeoffs.
Make cost effective solutions
If you fall in love with LLM, you start to see how every problem can be solved by LLM. This can backfire if you have not calculated the LLM API costs beforehand.
Have a look at this analysis to understand how LLM pricing varies across vendors.
To a man with a hammer, everything looks like a nail - Abraham Maslow
Model distillation
Distilling LLMs into smaller models is a crucial skill for companies relying on LLMs. When the task at hand has low complexity and low drift, it may be possible to generate outputs with LLMs to train an in-house model. This can help reduce the cost of using LLMs, which is especially relevant for companies using LLMs at scale for chatbots or summarization.
Researching techniques to train open-source models like FLAN with reinforcement learning can help accomplish the same tasks while reducing costs.
Evaluation methodologies
LLMs are quite good at generative applications but evaluation of generation is still very hard. Research on evaluation can focus on developing more effective methods for evaluating LLMs' performance, such as exploring new metrics, developing new benchmark datasets, and designing more effective evaluation methodologies.
LLM for making natural language interfaces
It is now possible to prime or train LLMs to make natural language interfaces with databases or apps. This requires understanding the user access patterns and creating training data manually or logging their interaction to convert them to training data.
Robustness and out-of-distribution generalization
For many industrial applications, few shot prompts are not enough. Hence we need to train the LLMs. This brings similar challenges of adversarial robustness, out-of-distribution detection, and handling noisy or low-quality input. We need to develop strategies to mitigate these vulnerabilities or develop new methods for OOD detection.
Long text generation and understanding
As the context length of LLMs increases, it unlocks new possibilities where we can give more context to give rich experience/personalisation. But a longer context comes with its own challenge which makes it slow and costly. How to apply the concepts like map reduce to make generation faster and more reliable?
Hallucination
Hallucination, in the context of LLMs, refers to the generation of output that is not grounded in reality or contradicts factual information. We need to develop techniques to mitigate this issue in LLMs, such as exploring methods for detecting and correcting hallucinatory output, designing effective training data to reduce the likelihood of hallucination, or exploring the use of external knowledge sources to ground LLM output in reality.
Ex. Just adding below to prompt reduces hallucination
Answer the question as truthfully as possible, and if you're unsure of the answer, say "Sorry, I don't know".
Language model as knowledge graph
Microsoft’s Copilot uses a knowledge graph containing all the interactions of a user. This allows them to have a memory of user-generated data which allows it to give a more personalised experience. LLMs can be used for extracting structured information from unstructured data or reasoning with LLMs using a knowledge graph. This allows companies to improve the accuracy and efficiency of their NLP systems.
Parameter efficient fine tuning
If you are fine tuning large FLAN models / EleutherAI models, doing parameter efficient fine tuning is essential to run experiments faster. Techniques like LoRA can give a similar performance while just training 2-5% new parameters without a significant drop in performance.
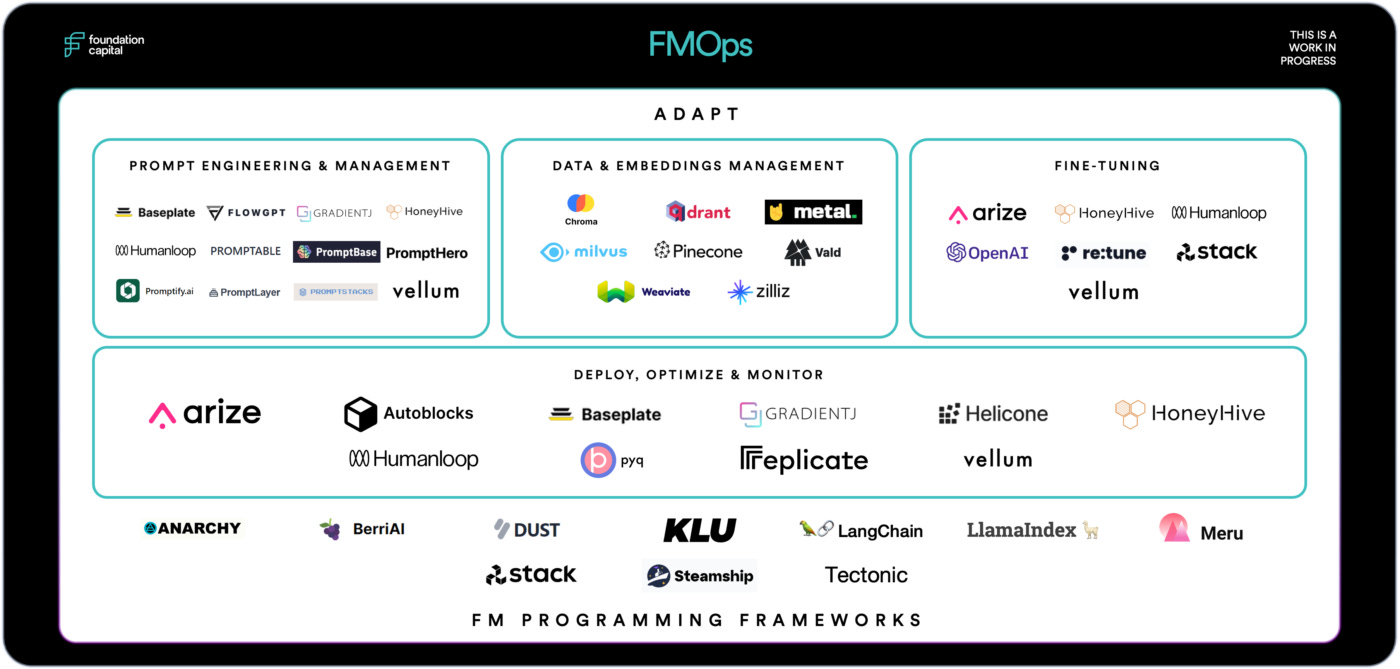
Embrace new tools for faster experiment and releases
A new stack is emerging to adapt, deploy and monitor the deployment of LLMs. Companies which learn to leverage these tools can have an advantage over other companies because they can iterate faster.
Winners in every space will be those who can spin the flywheel faster 🚀
Adapt → Deploy → Monitor → Fix ♻️
Closing thoughts
It is a fact that many endeavours previously deemed arduous or unattainable have now been rendered feasible. As a result, corporations may no longer have the need for as many researchers. On the other side, businesses that were once unable to afford researchers can now employ the power of LLMs. So companies with or without researchers can now produce comparable outcomes - truly, a level playing field!
In the past, a team would require at least one applied scientist per task. However, in the present day, that same scientist may craft numerous prompts or fine-tuned LLMs for diverse applications within a week's time.
It is my estimate that the demand for NLP researchers will go down, while the need for full-stack NLP engineers shall rise. Though we may have failed in our attempts at web3, every application shall henceforth be powered by AI.
Do share your thoughts in the comments section, or via the channels of Twitter and LinkedIn. And if you do not find this discourse amusing, do share it with a curse.
Come join Maxpool - A Data Science community to discuss real ML problems!
Connect with me on Medium, Twitter & LinkedIn.
Credits: Hugs to my friends Ankur Bohra & Goku Mohandas for reviewing and suggesting edits.