


NLP Tricks For Domain Adaptation
Fine tuning models to your data


Photo by Toa Heftiba on Unsplash
I am seeing a lot of interesting work from non-US groups. Researchers of Asia and Europe do not have resources similar to the US and work naturally under scarcity. There is no doubt on how scarcity brews innovation. These three papers caught my eye recently.
Earlier I have written on how to make new language models with transformers. As a follow up to it I am going to discuss better domain adaptation of language models with state of the art techniques from papers released recently. I am absolutely blown away with their results and it matches with my experiments of using LM with extremely resource-scarce codemix(Roman Hindi + English) data.
We discuss similar results in our SemEval paper “Tiny Data Specialists Through Domain-Specific Pre-training On Code-Mixed Data”. Our finding was to get a superior sentiment classification model for codemix data using just 14000 Indian tweets.
We show that a biLSTM(<10M) with domain trained fasttext embedding performs better compared to LM+task finetuned XLM-R(~500M) which supports codemix out of the box.
Domain adaptation in real-world scenarios

It has become extremely pervasive to use transformers these days. Every kid on the block just loves to throw transformer to the problem. But there are problems with transformers too.
Transformers do have OOV issue. It’s just that it doesn’t throw any error which is kind of a soft bug problem
Transformers are costly to fine-tune for domain
Transformers are inefficient in learning new domain words i.e data inefficient
In favor of vocab addition
Domain adaptation essentially means we are training the model for a particular domain text like medical or scientific. In such cases, models have to deal with unseen words where a bert-base-uncased converts dementia into dem ##ent ##ia. It just breaks unseen words into smallest chunk-of-char supported by its vocabulary.
It starts associating words ending in ##ia as diseases due to ##ia used in disease names. This can cause problem for words like euthymia which is not a disease.
OOV leads to inefficient and costly learning. It leads to longer tokenization which unleashes quadratic hell. Yes, linear transformers are coming but it still leads to poor word understanding.
So the immediate thing to do is vocabulary addition. Generally, people just add the unseen vocab to LM which are initialised with a random embedding. This means the model has no knowledge about this new word dementia and will learn it on LM finetuning on domain text.
Improving Pre-Trained Multilingual Models with Vocabulary Expansion throws good light on techniques for vocab addition.
In favor of LSTM
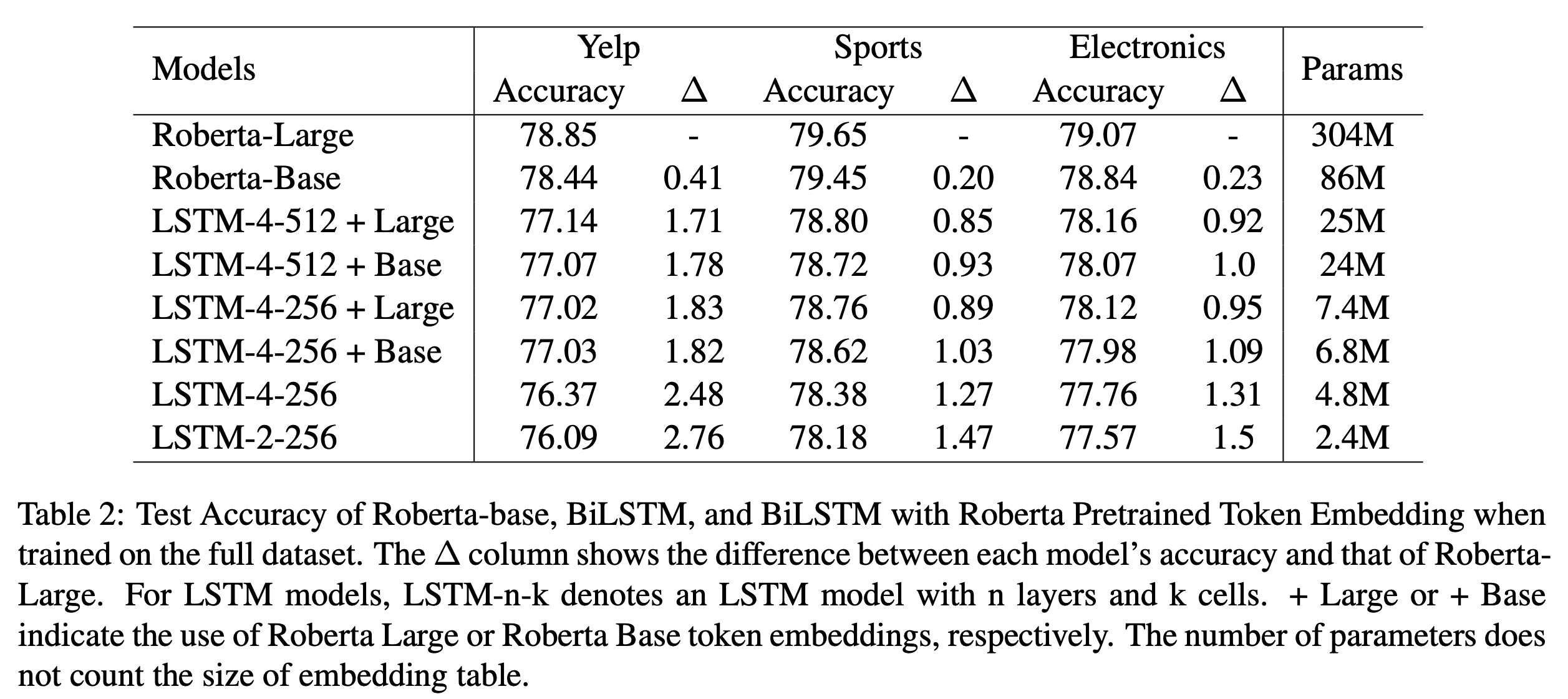
To Pretrain or Not to Pretrain shows the performance of vanilla LSTM is almost near to that of transformers when domain data is large. Hence we can train ULMFiT/LSTM with vocab addition.
In favor of transformers
Pretrained Transformers Improve Out-of-Distribution Robustness show that transformers generalise better. Hence it’s worth probing into transformers.
From our previous discussion, we are convinced that we should add vocab but how to do it! Is there a way to initialise new vocab embeddings better?
We can find these answers in Inexpensive Domain Adaptation of Pretrained Language Models.
Ways of adding vocab

Bad idea
Replace all embedding of LM with word2vec
Replace embedding of LM with word2vec for common words between LM and word2vec.
The above methods lead to poor result as it will cause the LM to lose out on its transformer trained superior embeddings.
Good idea
Add LM unseen vocab+emb from word2vec. This leads to better results as now we are bootstrapping new word embeddings with something better than random initialisation. And we do not lose out on the old word embeddings.
Even better
We can train a matrix W which learns to transform embeddings for common words from word2vec to LM. This probably leads to the fusion of knowledge of LM and word2vec.
The LM’s new embedding is updated such that
For common words -> 0.5(LM emb + word2vec*W)
For LM unseen words -> word2vec*W
The results of this method are very impressive!

So my new workflow might be to do this word2vec operation on a transformer model when domain data is a bit different. We can also do the same with pretrained LSTM models.
Conclusion
Use LSTM when training dataset is large
Add new vocab to LMs (with some frequency cut-off)
Modify old and bootstrap new vocab embedding with domain word2vec
I hope these tricks will come helpful in your future modelling.
Do you have any suggestions for domain adaptation?
Come, tell me your tricks 😬
Come join Maxpool - A Data Science community to discuss real ML problems
Ask me anything on ama.pratik.ai
You can try ask.pratik.ai for any study material.