
3 Ways To Make New Language Models 👷
💯 transfer learning

Photo by Patrick Schneider on Unsplash
We started with open source ‘code’ contribution. Now we are at a phase where we do open source ‘model’ contribution.
But how to make new language models?

Scenario 1: Model from scratch
Recently, Huggingface released a blog on how to make a language model from scratch. It consists of training a tokeniser, defining the architecture and training the model.
Pros
You can make a model on your custom text or a new language
You have complete control of model parameters. If you are looking to make a model which works on a text of fixed domain with less vocab, you can make the smallest possible model. Helps in latency!
Cons
You need to have a decently large dataset
Training is going to be costly

Scenario 2: Transfer learning
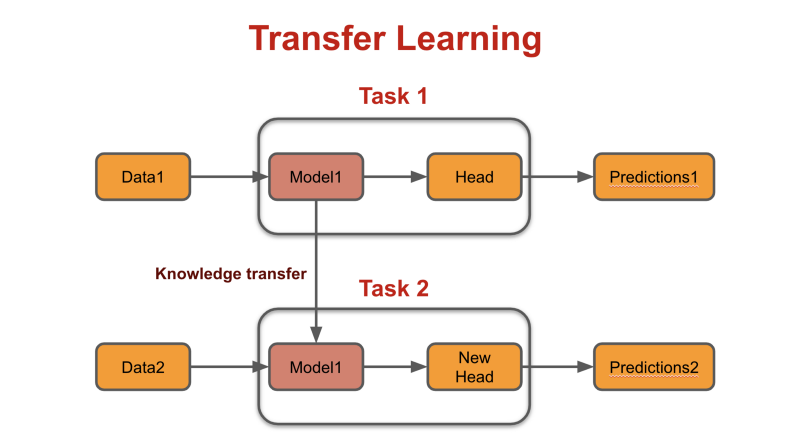
This is the common approach where we take a pretrained model like AWD-LSTM or ALBERT and then fine-tune it for our task.
Pros
You can train with less data
Training is cheaper
Cons
If your text has many new words, they will be split into very small chunks or even characters if it’s a subword model like BERT. If it’s a word-based model, all new words will be <unk> tokens.
Splitting into very small chunks and <unk> can lead to poor performance of the model.

Scenario 3: Transfer learning with new vocab addition
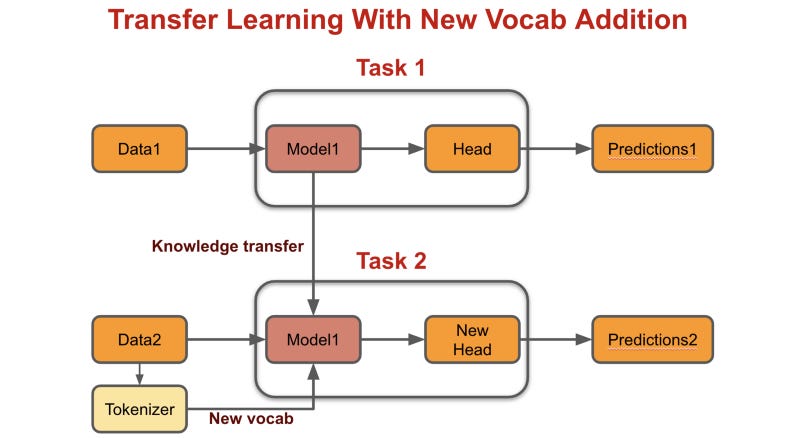
This methodology is the sweet spot between using transfer learning and making a model from scratch.
AWD-LSTM (A bite of history)
This was first explained nicely in the fastai lectures. Using the below convert_weights function they add zero vectors to the embedding matrix of AWD-LSTM for new vocab. AWD-LSTM has a vocab of ~33k and hidden of 400. If you add 10k new vocab, your total vocab is now 43k.
So the embedding matrix is now changed from (33k, 400) to (43k, 400) where the new 10k rows added are just 0 vectors of size hidden.
Using this methodology, we don’t need to start from scratch for old vocab which is a huge advantage! 🔥
Fastai code is superb and does all these automatically without worries. The problem is how to do this with transformers library? 🤔

Adding new vocab to transformers 🚀
On a lonely night with no progress of accuracy on a problem we were working with, this solution struck to me. We had tried out transfer learning with AWD-LSTM, BERT, ALBERT, XLM-R, and making a new model from scratch too.
Nothing worked for us because we had 2 problems:
We had huge OOV issues
We had very less training data. We scraped data and again didn't have enough data. Available models are trained on GBs of data and we hardly had 50MB of data.

Solution
I thought why not try convert_weights approach for transformers.
Model selection
I tried two models canwenxu/BERT-of-Theseus-MNLI and TinyBERT. I selected these for a few reasons
Performance: Both have almost BERT-base performance
Library availability: Both can be used with transformers library
Model size: Since I had very less training data, I wanted the smallest model as the amount of data required is proportional to no. of parameters. As of writing, these are the smallest model with BERT-base level performance.
Theseus has 66M
AWD-LSTM has 24M
TinyBERT has 15M parameters 🐼
I didn’t select distilBERT as Theseus has same parameters and better performance as shown in the snap.

BERT-of-Theseus-MNLI https://arxiv.org/pdf/2002.02925.pdf

TinyBERT https://arxiv.org/pdf/1909.10351.pdf
UPDATE:
Now other range of small BERT models have also become available.

https://github.com/google-research/bert/

https://github.com/google-research/bert/
These models have been made available in Transformers library and you can read this paper to understand the motivation and methodology.
Basically, we don’t need a model as big as BERT-base all the time and the latency requirements push a need to make smaller models.
Overall the results of these small models are very very impressive.

Add vocab to model
So here is how the changes look like. You need to choose appropriate tokenizer as per your model. Theseus is a distilled model of BERT and hence uses BertWordPieceTokenizer.
The below method takes the dataframe containing column ‘text’ and fits a wordpiece tokenizer for the vocab_size breaking words into subwords as needed. Then we export the vocab and load it as a list.
Now we add the vocab to the original tokenizer and pass the length of tokenizer to model to initialise new empty rows for new vocab.
You need to use this method after the tokenizer and model are loaded in the run_language_modeling.py
New vocab size
Be careful about vocab_size!
If you add a huge number of new vocab, the model might become inferior. It’s a parameter to be hyper-tuned.
Once you have the model, do a before/after analyses of the tokenization with old and new model.
The new model should tokenize a sentence in less number of tokens.

Results 📊
I was able to get the same metric and faster task training with TinyBERT. Although this was for a competition where the goal is to get a high score, it can save a ton of headache and money for inference in the production scenario 😍
I highly recommend using TinyBERT and suggest being open to evaluating smaller models before finalising a heavy transformer model 🐵
Modern NLP
All the latest techniques in NLP — Natural Language Processing