
LLM Chronicles #8: How To Select Encoder For Semantic Search & RAG?
A systematic approach to selection of encoders


Come join Maxpool - A community to discuss industrial problems of leveraging LLM and vector search. You can join with this link - join.maxpool.ai.
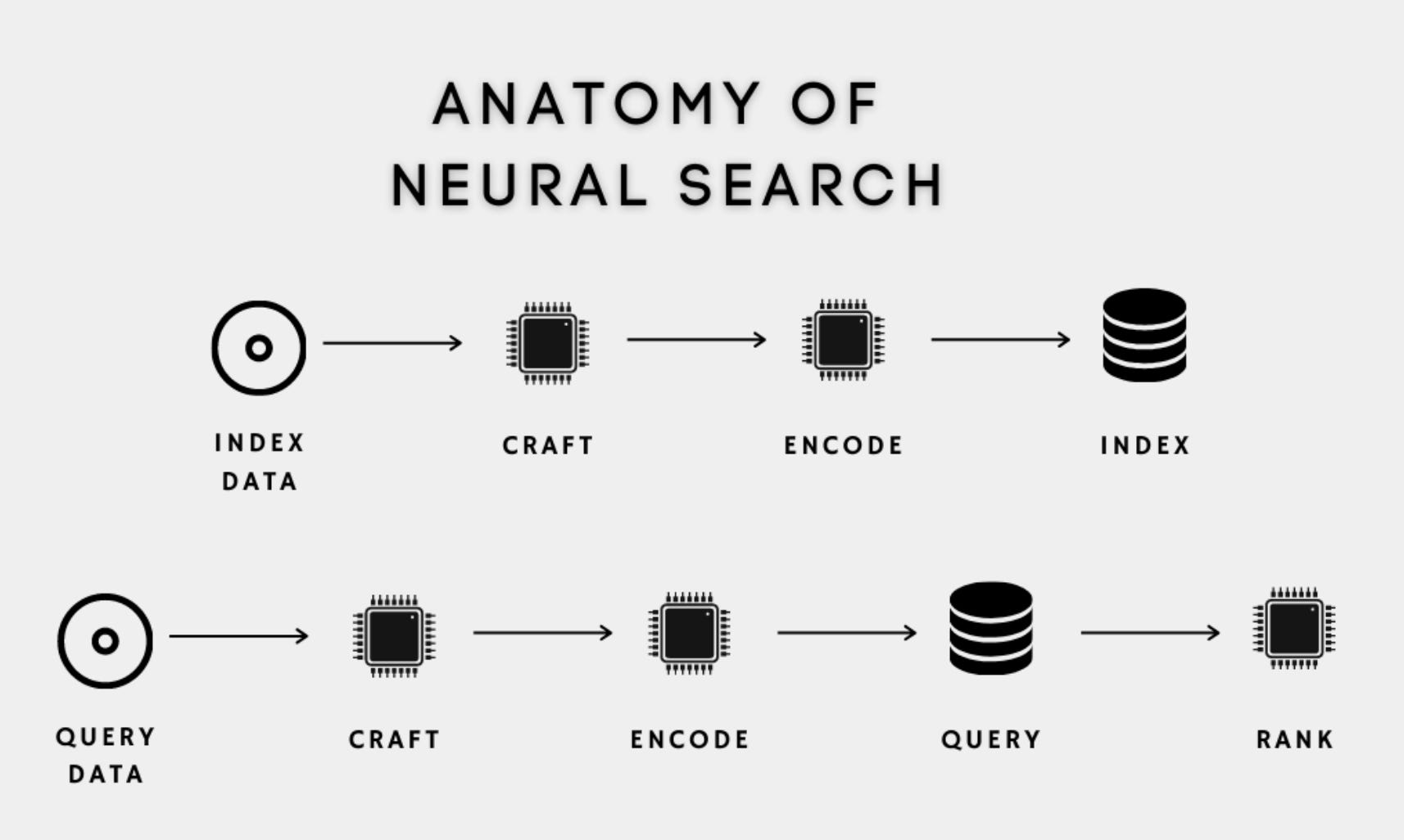
The industry is crazed about Retrieval Augmented Generation (RAG). Every company wants to build a Q&A engine which can help improve the efficiency of internal or external users. But often they are powered by semantic search where the selection of text encoder plays a crucial role in the performance. However, with the wide variety of options available, selecting the best text encoder can be a daunting task.
Here we will explore these factors while choosing a text encoder:
Leveraging MTEB benchmarks
Custom evaluation
Tradeoff between private and public encoder
Chunking
Language support
RAG evaluation
LLMs for ranking
Performance metrics
Public benchmarks
The most reliable source for assessing encoder capabilities is the MTEB (Massive Text Embedding Benchmark). With this benchmark, you can choose encoders according to vector dimension, average performance for retrieval, and model size. From the table we can see some open-source models beating OpenAI embedding API. Although we should take it with a pinch of salt because there is no perfect evaluation benchmark nor do we have a complete idea of what the models are trained on.
People often ask - How good is the Cohere embedding API? Sadly no metrics are released for the same and it’s difficult to confirm without testing it on your dataset. This holds true for all open-source encoders as well. Always evaluate on your dataset before the final selection. This brings us to the topic of custom evaluation.

Custom evaluation
At times, encoders may not exhibit optimal performance when handling sensitive information. It may be necessary to assess their performance using our internal dataset.
Method 1: Evaluation by annotation
In this we generate a dataset and setup annotation to get a gold labels.
Repeat the below process with different encoders & BM25 (to avoid biasing results for a particular encoder)
Index your docs with an encoder
Create synthetic queries using a generator like GPT with few shot examples
Query index with these queries
Save top 20 results for the query
After getting the above results:
Merge results for each query from all indexes
Setup annotation guidelines (0/1 class, 1-10 match score, relative rank)
Setup annotation task for rating the query<>result
After the annotation you can use these metrics to quantify the performance. Read this blog to more about them.
Rank unaware metrics
Recall@k
Precision@k
F1@k
Rank aware metrics
MRR(Mean reciprocal rank)
NDCG(Normalized Discounted Cumulative Gain)
The annotation should be done in a way which allows us to know the desired metric. In my experience its easy to start with rank unaware metrics.
Method 2: Evaluation by model
In this we execute the data generation steps similar to Approach 1, but employ a language model (LLM) or a cross encoder as the evaluator. This enables the establishment of a relative ranking among all encoders. Subsequently, a manual assessment of the top three encoders can yield precise performance metrics.
Method 3: Evaluation by clustering
Conduct diverse clustering techniques and examine the coverage (quantity of data clustered) at distinct Silhouette scores (indicating vector similarity within clusters). Experiment with algorithms like DBSCAN and HDBSCAN, adjusting its parameters for optimal performance selection.
Tradeoff between private and public encoder
Query cost
Semantic search requires the embedding API service to be highly available otherwise the latency of results can be poor which can affect the user experience adversely. APIs from embedding providers like OpenAI are highly available and we do not need to manage the hosting. In case we go with an open source model, we need to engineer the solution. This needs to be done based on the size of the model and latency requirements. Models upto 110M parameters(500MB) can be hosted with CPU instance but larger models may require GPU serving to cater to latency.
Indexing cost
Setting up the semantic search requires indexing of the docs which can cost a non-trivial amount. Since the indexing and querying require the same encoder, indexing cost will depend on the encoder service. It's prudent to store embeddings in a separate database to enable service resets or reindexing onto an alternate vector database. Failing to do so would entail recalculating identical embeddings.
Privacy
Sensitive domains like finance and healthcare demand stringent data privacy. Consequently, services like OpenAI might not be viable options.
Search latency
Latency grows linearly with the dimension of the embeddings. So lesser dimension embeddings are preferred.
Storage cost
It's crucial to consider Vector DB storage cost if your application requires indexing millions of vectors—storage cost scales linearly with dimension. Dimensions can be one of 384, 768, 1024, 1526. OpenAI embeddings come in 1526 dim which pushes storage costs to the maximum. For estimating storage cost, you can get a ballpark on avg units(phrase/sent) per doc and extrapolate it.
Lets compare price for storing 1M vector in different vendors (updated on 13 Aug)
Pinecone

Weaviate

Qdrant

We can see price to be turning out in a similar range. Although there are other features like latency, hybrid search, metadata support, querying capabilities, pre-filtering, ease of scalability and support SLA to be considered while selecting the vendor.

Open source database
You can also setup your own database with open source solutions like Milvus, Weaviate, Qdrant and Elasticsearch. This will incur an additional engineering overhead for maintenance and support.
Chunking
How you decide to tokenise(break) the long text can decide the quality of your embeddings and hence the performance of you search system. You can read this post on how to deal with long documents. Alternatively, you can also exploit summarisation techniques to reduce noise, text size, encoding cost and storage cost with many summarisation techniques with LLMs. Chunking is an important yet underrated topic. It can require domain expertise similar to how we do feature engineering. For ex. chunking for python codebases might be done with prefixes like def/class.
Language support
When the application is across the geography, the language of user can be different from the document.
Approach 1
Use a multilingual sentence encoder to represent text from many language to similar vectors. Cohere provides a multilingual embedding API. Since we do not have the metrics for it in comparison to others, do evaluate before using. You will find some open-source options on MTEB.
Approach 2
Use an English encoder alongside a translation system
Detect the language of user query (ex. French)
Translate query to English (French → English)
Embed query
Search documents
Translate all top-scoring documents to the user’s language (English → French)
LLMs for ranking
There is also a motion on using LLM for ranking. They seem to be beating powerful rerankers but are also prohibitively expensive and slow. You can read these for more information on the approaches:
Large Language Models are Effective Text Rankers with Pairwise Ranking Prompting
Is ChatGPT Good at Search? Investigating Large Language Models as Re-Ranking Agent
RAG evaluation
Often companies use encoders for semantic search to power RAG system. The performance of these systems can be improved with better combination of various parameters. This is a lightweight evaluation tool for question-answering using Langchain. It is not exhaustive but can give you a good starting point.
This is how it works:
Ask the user to input a set of documents of interest
Apply an LLM (
GPT-3.5-turbo) to auto-generatequestion-answerpairs from these docsGenerate a question-answering chain with a specified set of UI-chosen configurations
Use the chain to generate a response to each
questionUse an LLM (
GPT-3.5-turbo) to score the response relative to theanswerExplore scoring across various chain configurations

Conclusion
In conclusion, the process of selecting the suitable text encoder for semantic search is a critical step that significantly impacts the performance of your application. With the vast array of options available, making this choice might seem overwhelming, but a systematic approach can simplify making the decision.
Come join Maxpool - A community to discuss industrial problems of leveraging LLM and vector search!