
Semantic Search On Documents
Encoding text longer than 512 tokens


Transformer models have become the defacto for making semantic search. These are often limited by the 512 token limit. How do you make search for documents which are longer than this?
The representation can also get noisy for long text(>50 tokens) which deteriorate the performance of search. What should we do in such cases?
Below are the techniques for making semantic search for long texts.
Summarisation
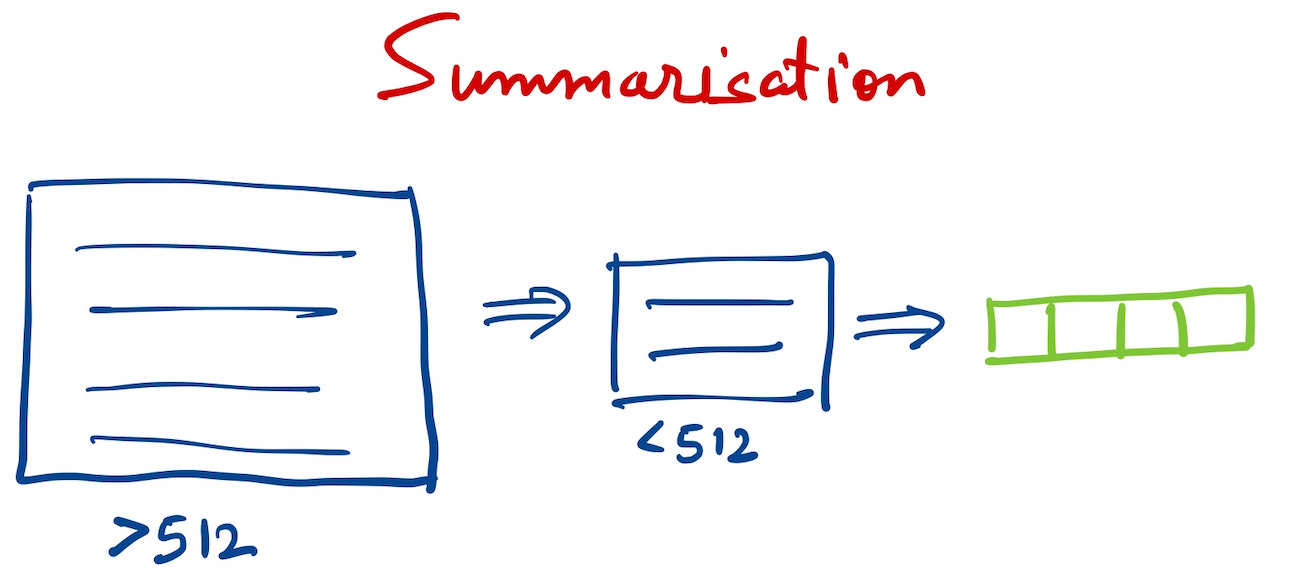
Reduce the size of text by summarisation
Extractive summarisation
TextRank - Fast and decent
BERT extractive summarisation - Slow and effective
Performance of BERT extractive summarization can depend on domain specific the text is. You can choose your own domain trained BERT for it.
Abstractive summarisation
Use a model like BART/TLDR or GPT3 for abstractive summarization. This will be slow but slightly more effective than extractive summarization.
Break into chunks
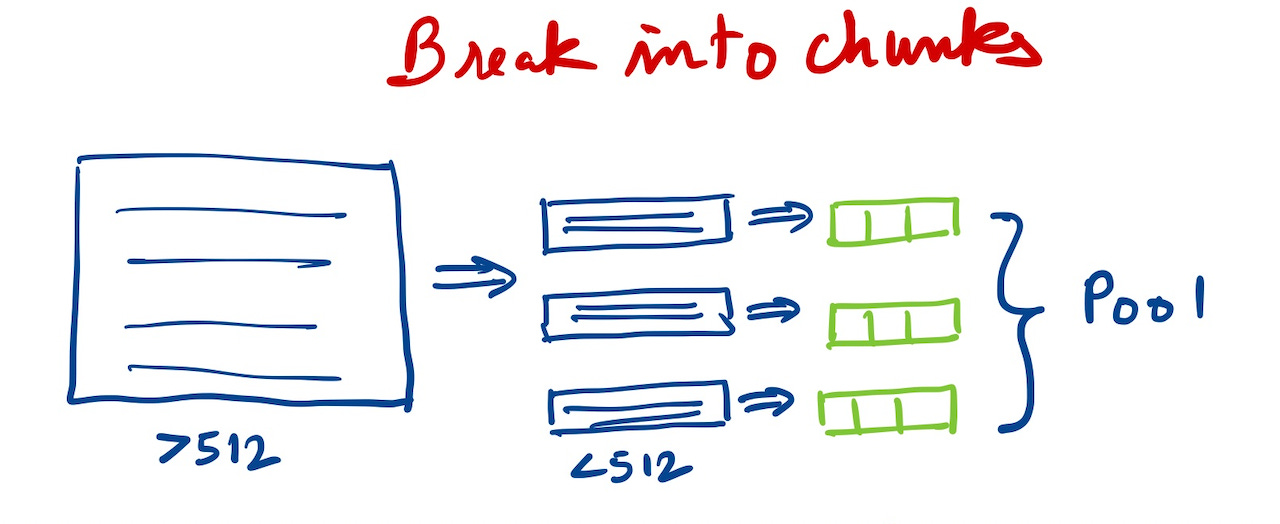
Break data into chunks
sentence level
paragraph level
threshold text length
Once you encode these smaller chunks
you can keep them separate with metadata about parent doc from which chunk was created
combine vectors by pooling for document encoding
Use a longer text encoder
Use an encoder like Longformer which supports longer text. This will require GPU to work or can get too slow.
Extract keywords and then encode

Extract the keywords using unsupervised extraction methods like YAKE, RAKE, KeyBERT. Then encode these words and create a mean vector.
The encodings of keywords will not be contextual since we throw away the surrounding text
You can also train your own embedding model like fasttext over the text. Then use model to encode keywords.
This will be fast and decent.
TFIDF + SVD/PCA/UMAP
Fit a TFIDF over the text and train a dimensionality reduction over it. This might be suitable only if you do not have text encoder for your domain. The results might not be great.
You can do this with gensim.
Conclusion
Breaking into chunks is one of the most used methods to tackle this problem. You can also use a combination of these techniques.
Come join Maxpool - A Data Science community to discuss real ML problems!