


Better Semantic Search With Unsupervised Training Of Sentence Encoder
Making better domain text encoders with TSDAE


For some time now I have been looking for methods to fine-tune models for semantic search. The trouble is I never have the pair data for training via siamese methods. The simplest method that comes to mind is LM fine-tuning. But is there anything better?
My favorite UKP Lab just released a methodology TSDAE that helps exactly with this. Now we can finetune model with just sentences and get superior results. Having a better encoder helps with semantic search as well as other downstream tasks.
How it works?

“An important difference to original transformer encoder-decoder setup presented in Vaswani et al. (2017) is the information available to the decoder: Our decoder decodes only from a fixed-size sentence representation produced by the encoder. It does not have access to all contextualized word embeddings from the encoder. This modification introduces a bottleneck, that should force the encoder to produce a meaningful sentence representation.
By exploring different configurations on the Semantic Textual Similarity (STS) datasets (Cer et al., 2017), we discover that the best combination is: (1) adopting deletion as the input noise and setting the deletion ratio to 0.6, (2) using the output of the [CLS] token as fixed-sized sentence representation (3) tying the encoder and decoder parameters during training.“

Performance comparison
TSDAE outperforms all out-of-the-box models.
It beats USE-large by slight margin because USE-large was trained for AskUbuntu and CQA.
TSDAE is significantly better than previous unsupervised approaches.

Previous approaches
“Recent work combines pre-trained Transformers with different training objectives to achieve state-of-theart results. Among them, Contrastive Tension (CT) (Giorgi et al., 2020) simply views the identical and different sentences as positive and negative examples, resp. and train two independent encoders; BERT-flow (Li et al., 2020) trains model via debiasing embedding distribution towards Gaussian. For more details, please refer to Section 5. Both of them requires only independent sentences. By contrast, DeCLUTR (Giorgi et al., 2020) utilizes sentence-level contexts and requires long documents (2048 tokens at least) for training. This requirement is hardly met for many cases, e.g. Tweets or dialogues. Thus, in this work we only consider methods which uses only single sentences during training.”
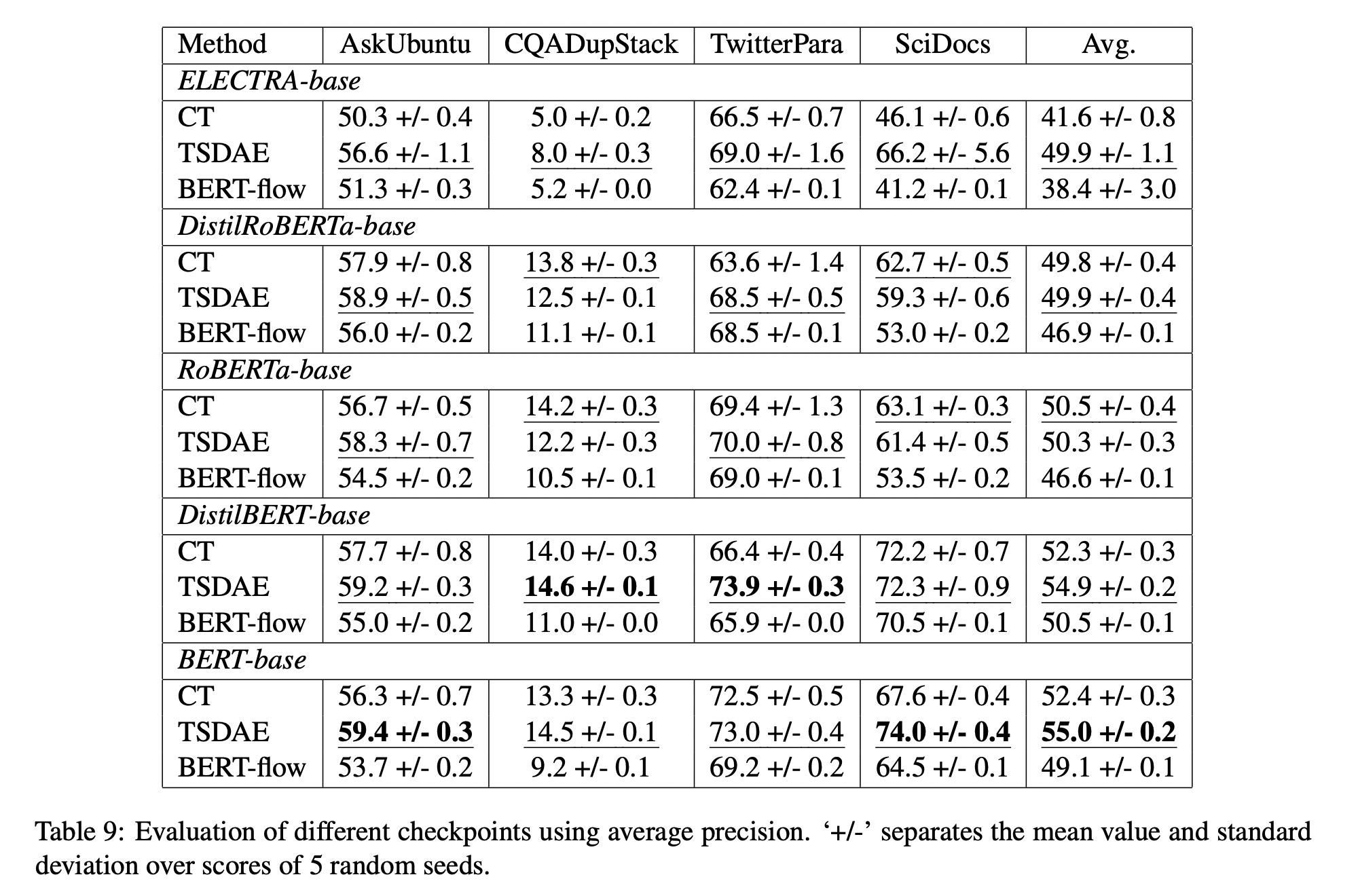
Which model to fine-tune?
You might think fine-tuning RoBERTa-base might give best results but these results show BERT-base is better. I am a bit shocked by this result 🤔
DistilBERT-base is performing almost same as BERT-base and so we should go with it.
Performance comparison difference on STS

“We find the (sole) evaluation on STS problematic for several reasons. First, the STS datasets consists of sentences which don’t requiring domain specific knowledge, they are primarily from news and image captions. Pre-trained models like USE and SBERT, which use labeled data from other tasks, significantly outperform unsupervised approaches on this general domain. It remains unclear if the proposed unsupervised approach will work better for specific domains.
Second, the STS datasets have an artificial score distribution that dissimilar and similar pairs appear roughly equally. For most real-word tasks, there is an extreme skew and only a tiny fraction of pairs are considered similar.
Third, to perform well on the STS datasets, a method must rank dissimilar pairs and similar pairs equally well. A method that identifies perfectly similar pairs, but has issues to differentiate between various types of dissimilar pairs, would score badly on the STS datasets. In contrast, most real-world tasks, like duplicate questions detection, related paper finding, or paraphrase mining, only require to identify the few similar pairs out of a pool of millions of possible combinations.
Overall, we think that the performance on the STS datasets does not correlate well with downstream task performance. This has also been previously shown in Reimers et al. (2016) for various unsupervised approaches.”
Conclusion
First, try USE-large and SBERT-base-NLI as benchmark models. Fine-tune DistilBERT-base on your data. Make internal benchmark data or use clustering metrics for final selection.
Come join Maxpool - A Data Science community to discuss real ML problems!