


LLM Chronicles #5: GPT For Ecommerce Search Engine With Pinecone
Offload complex query parsing to LLMs


Yeah yeah, we all need embedding search but it does not work well in certain scenarios. Companies often use 2 types of hybrid search - 1) weighted scoring and 2) filter and rerank. In the former, you do a weighted average of sparse vector scores like BM25/SPLADE & dense vector score. In the latter, you filter first by criteria and then sort by dense vector score. The 2nd is quite prevalent in e-commerce.
Let’s look at this query - Mocha coffee by Maxim 50 packets
We are looking for a Mocha coffee by brand Maxim which has 50 servings. This is not the case where embedding search alone is enough. We need to parse out the query.
branch = Maxim
item - Mocha coffee
size - 50How can we leverage GPT for query understanding? Traditionally companies develop ML-based query parsers and populate an Elasticsearch/Solr query with the entities detected. They train this parser periodically to keep it updated with new query patterns, brands & products.
We know GPT has an understanding of brands and products till Sep 2021. It is also general enough to work with recent things. So let’s try GPT.
We first define how filter query works in Pinecone with a few shot prompt. These are taken from Pinecone docs.
prefix_prompt = """How Pinecone query works in Python
You can add metadata to document embeddings within Pinecone, and then filter for those criteria when sending the query. Pinecone will search for similar vector embeddings only among those items that match the filter.
```python
index.query(
vector=vector,
filter={
"genre": {"$eq": "documentary"},
"year": 2019
},
top_k=1,
include_metadata=True
)
```
More example filter expressions
A comedy, documentary, or drama:
{
"genre": { "$in": ["comedy", "documentary", "drama"] }
}
A drama from 2020:
{
"genre": { "$eq": "drama" },
"year": { "$gte": 2020 }
}
A drama from 2020 (equivalent to the previous example):
{
"$and": [{ "genre": { "$eq": "drama" } }, { "year": { "$gte": 2020 } }]
}
A drama or a movie from 2020:
{
"$or": [{ "genre": { "$eq": "drama" } }, { "year": { "$gte": 2020 } }]
}
###
"""Now we define the schema of the entities indexed in Pinecone. These are product attributes which can be used to form the Pinecone query.
schema = """Schema of the data which is indexed in our vector database
release_date: datetime
category(str): can be cloth/shoes/biscuits etc
product company(str): gucci/nike/nestle etc
size(int): size of item
gender(str): male/female
keywords(list of str): words which could not be assigned to any other field
Now for the query given, dont write any explanation for the query. Be sure to check words in query to every field of schema. Just write the filter between ```
query: """Now we give a query and form the final prompt.
query = "Mocha coffee by Maxim 50 packets"
final_prompt = prefix_prompt + schema + queryUsing GPT4 we get this Pinecone filter which seems to be correct.

For query: mobile cover iphone max 14 skadioo matte finish
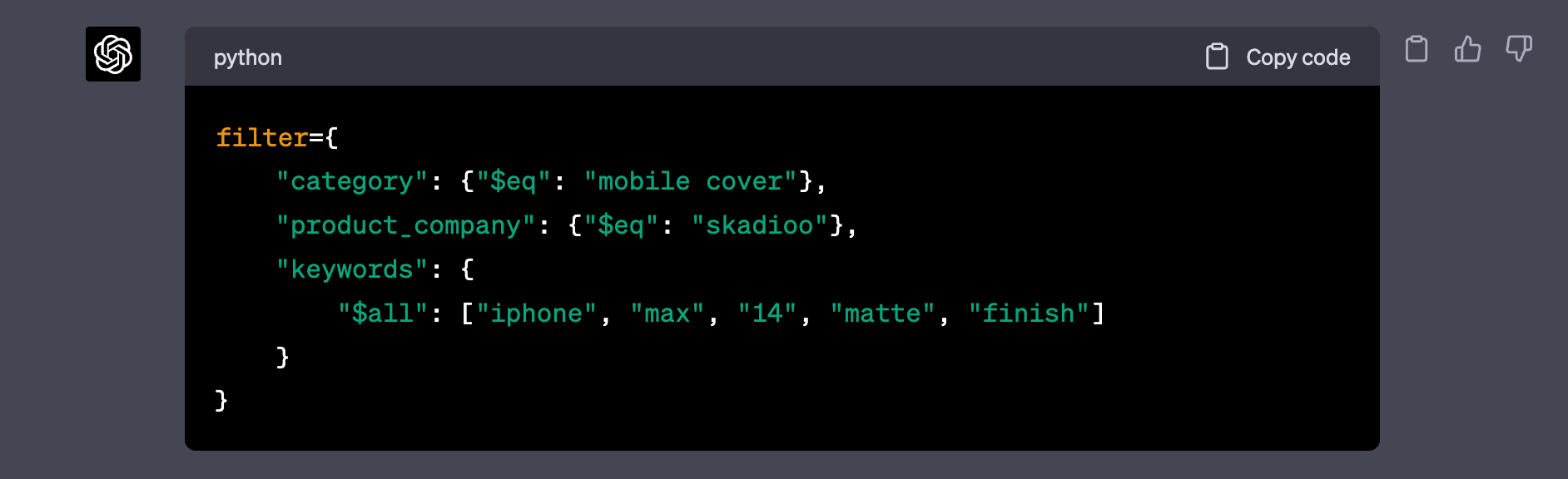
I tried a few queries and it worked decent. The outputs from gpt-turbo-3.5 were incorrect sometimes. Using GPT4 is going to be costly & slow, but we can train an open-source model like MPT-7B once we have enough generations.
Try it out and let me know! Do check out previous articles in the LLM chronicles.
Come join Maxpool - A Data Science community to discuss real ML problems!