
Finetuning GPT3 With OpenAI
Its amazingly powerful


GPT3 is quite impressive with its few shot capabilities. But you hit a limit due to prompt length limit. You end up in a zone which is better than any off-the-shelf model but not what you were hoping. You wonder if you could just fine tune the model.
Recently OpenAI release API to fine tune model with your dataset. It trains the model on the language modeling task using the “prompt” and expected “completion” pairs. You can use it for any use case with text.
Training limits
You can fine tune curie, ada and babbage models. You cannot train the most powerful davinci.
OpenAI gives free 10 runs per month.
Before starting the experiments, I asked for increase in run limit. OpenAI responded saying they can increase the limit if I exhaust it.
The dataset size limit is ~100MB.
Shorter prompt
As I prepared data for the experiment, I realise I did not have to use the original long prompt I was using for the few shot prompt. You can remove the few samples in the prompt and keep only the text on which you need to predict.
This leads to faster completion and less API cost.
My data contained around 20k rows - 6MB in size.
Training
Before you start the training, you have to run a command to check the data. It gives you some suggestions. It suggests to autocorrect the data as needed which is an interesting user experience.
openai tools fine_tunes.prepare_data -f train.jsonl
It tells you estimate of queue time and train time from the dataset. Strangely, when I ran the fine-tune command it started training on the spot and training was also faster than the estimate.
openai api fine_tunes.create -t train.jsonl -v eval.jsonl --batch_size 2 -m curie --n_epochs 4
If we pass eval file, it evaluates periodically on the eval file. Later we can export the loss metric logs.
openai api fine_tunes.results -i ft-iC3SV > results.csv
It also allows to train classifiers and get classification evaluation metrics. For classification, make sure the class name is single word. This helps us get the word probability which becomes the probability of prediction.
openai api fine_tunes.create -t train.jsonl -v eval.jsonl --batch_size 32 -m curie --n_epochs 4 --no_packing --compute_classification_metrics --classification_n_classes 2 --classification_positive_class "CLASS1"
The fine tuning time for classification turned out higher than same for non-classification. It also took more time to start the task. Maybe the queue were long.
Training logs

Inferencing
There is a slight delay in the model getting available after the training. But once it is published, it runs without any errors. The first call to the model takes time as it gets loaded but then it remains warm for some time.
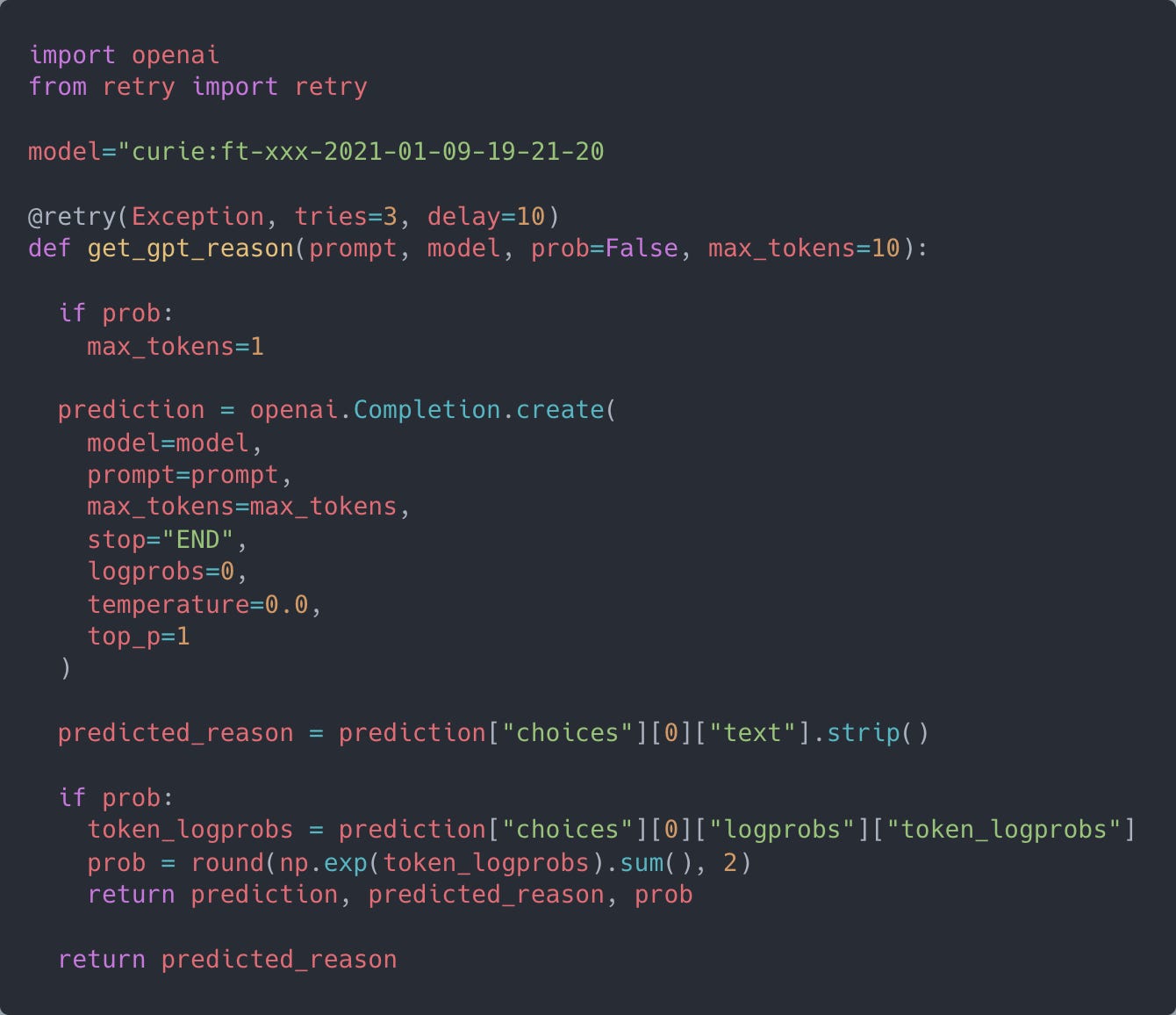
Get the code here.
The above function will return you the text generated. If you are dealing with classification, pass prob=True. This sets the max_tokens to 1 which we can later utilise to get probability of prediction using token_logprobs.
We set temperature and top_p such that it will sample the highest probility tokens which makes the prediction deterministic.
I was calling the model with a single process iterating over the samples to predict on. The iteration speed goes up from 1.3 to 2.5 samples/sec which means it scales up a bit when needed.
Result
The model trains really well and is able to generalise. The results are much better than the few sample prompt.
All in all a fine-tuned curie beats a few sample davinci.
Pricing
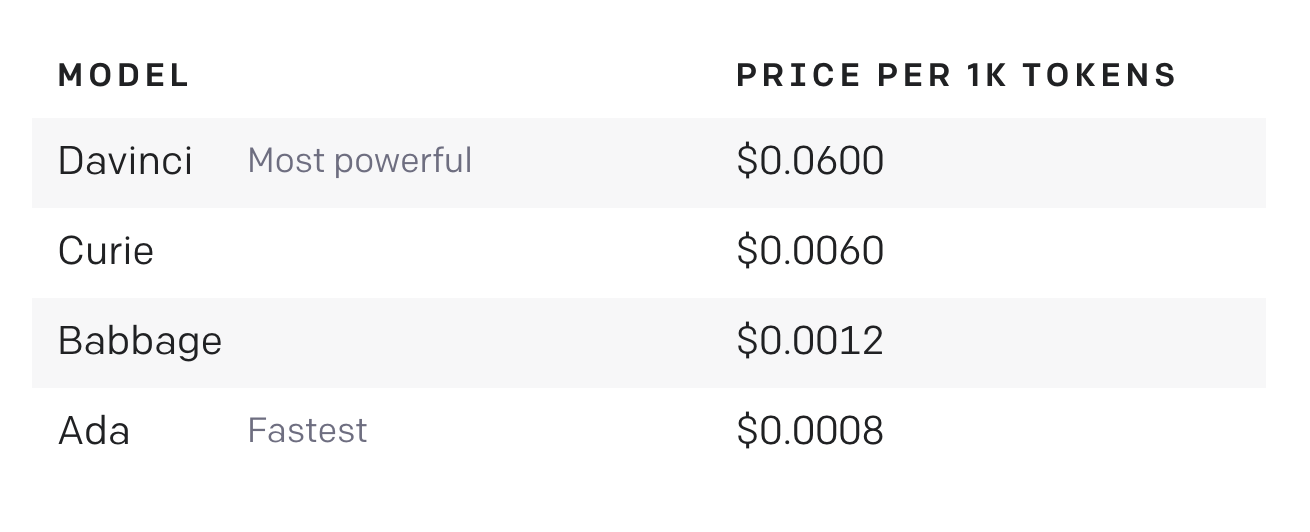
Completion model pricing
Fine tuned model pricing
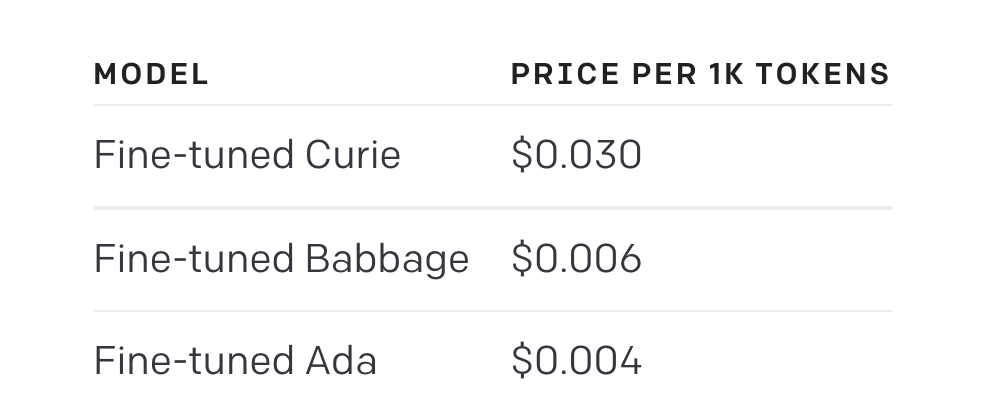
The hidden benefit is you get upto 10x cheaper inference compared to davinci since the prompt is really small and fine-tuned curie is 2x cheaper.
Overall experience
Working with finetuning was quite a pleasant experience. It is minimal and delivers on the promise. This was my first taste of getting a model trained by a service. This feels like the future. It gives us all engineers the same capabilities as top companies. It helps us focus on experiment design and not worry about the training/inferencing code or the infrastructure.
I really wish there was a UI where I can see the runs of my experiments and visualise the training loss. They can remove the n_epoch parameters and have early stopping. This will save time and resources for both. Currently the user has to keep a track of experiment name, datasets, run ID to get results and model ID to use.
Faster training and ETA after 1st epoch will be really helpful.
Come join Maxpool - A Data Science community to discuss real ML problems!
Hi Pratik - Great blog, thanks for sharing!
I think there's a minor mistake with the numbers you listed for finetune model pricing. I think those are the prices for training tokens, not for inference. From my calculation fine-tuned Curie is even 5 times cheaper than davinci (and requires probably a smaller number of context tokens, as you say).
Cheers