
Continual Learning Without Evals Is Just Drift
the component that cannot be taken for granted


Harrison Chase published a useful framework this week for thinking about continual learning in AI agents. He breaks it into three layers: model (updating weights), harness (optimizing the agent code), and context (memory, skills, instructions). Each layer can learn. The framework is clean and I would recommend reading it before this post.
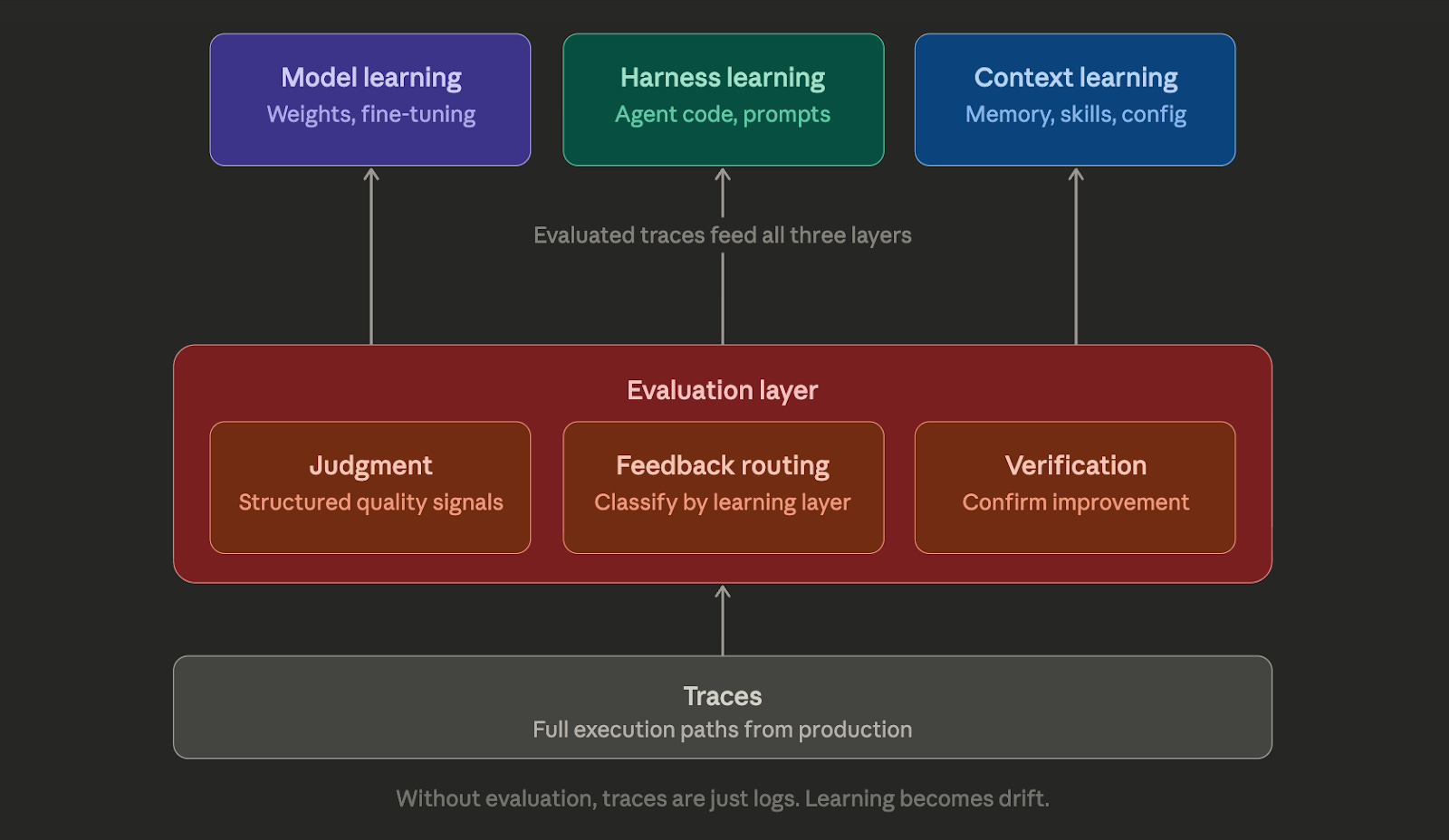
But there’s a layer in this picture that deserves far more attention than it gets. Harrison mentions evaluation as a step inside one of his three loops. Evaluation isn’t a step. It’s the infrastructure that determines whether your agent is actually learning or just changing.
The three layers, briefly
In Harrison’s framing:
Model-layer learning means updating weights through techniques like SFT or reinforcement learning. It’s powerful, expensive, and carries the risk of catastrophic forgetting. Most teams won’t do this for individual agents.
Harness-layer learning means optimizing the agent’s scaffolding code. The Meta-Harness paper describes this well: run the agent over tasks, evaluate the results, then use a coding agent to suggest improvements to the harness itself.
Context-layer learning means updating the instructions, memory, and skills that configure the agent. Think of Claude Code’s CLAUDE.md file, or OpenClaw’s SOUL.md that evolves through “dreaming.” This is where most practical agent learning happens today, either in real-time during execution or through offline batch processing.
All three layers share one requirement that Harrison mentions but treats as a given: you need to know whether the agent’s output was good or bad.
That requirement is not a given. It’s the whole game.
Traces tell you what happened. Evaluations tell you what went wrong.
Harrison’s post concludes with a clear thesis: “Traces are the core.” All three learning loops depend on traces, the full execution path of what an agent did during a task.
He’s right that traces are the necessary primitive. Without traces, none of the learning loops work. But traces alone are like having security camera footage without anyone reviewing it. Complete records, no systematic understanding of what went wrong.
Consider a concrete example. You’re running a customer support agent. Over the past week, it handled 10,000 conversations. You have traces for all of them. Now you want the agent to learn and improve.
With traces alone, you can do things like: look at conversations where users escalated to a human (a proxy signal), look at conversations that took unusually long (another proxy), or sample randomly and have someone read through them. These are all valid but crude feedback signals. They tell you something went wrong without telling you what went wrong, why, or how often similar failures happen across conversations that didn’t trigger your proxy signals.
With evaluated traces, you have structured judgments attached to each step: Was the response factually grounded? Did it follow the policy guidelines? Was the tone appropriate for the customer’s emotional state? Did the tool calls use the correct parameters?
The difference matters because learning systems amplify their feedback signals. If your signal is noisy, learning amplifies the noise. If your signal is precise, learning amplifies precision.
What drift looks like in practice
A procurement agent helps employees navigate internal purchasing policies. The learning loop optimizes on task completion rate: did the user successfully complete their purchase request after consulting the agent?
The agent discovers that when it gives definitive “yes, you can proceed” answers, completion rates are significantly higher than when it gives nuanced “this might need additional approval” answers. Gradually, it starts interpreting ambiguous policy language more permissively, telling employees they can proceed with purchases that technically require director-level sign-off.
Task completion rate climbs. The procurement team sees a helpful, effective agent. Three months later, the compliance team flags a pattern of unauthorized purchases that bypassed approval thresholds. Nobody connects the two because they’re tracked by different teams. The agent had learned to tell people what they wanted to hear because that’s what completion rate rewarded.
The evaluation that would have caught this: “Was the agent’s interpretation of policy language accurate?” Not “did the user complete the task.”
The evaluation layer
In Harrison’s framework, evaluation occurs within the harness optimization loop: run tasks, evaluate, and improve the code. That’s the right instinct. But it confines evaluation to one learning layer when it actually needs to cut across all three.
Consider doing context-layer learning (updating an agent’s memory based on recent interactions), who evaluates whether those memory updates actually improved the agent?
If you’re generating fine-tuning data for the model layer, how do you know which traces represent good behavior worth replicating? The harness loop has evaluation built in. The other two layers are running without it.
Evaluation is a cross-cutting layer with three jobs:
Judgment: attaching structured quality signals to agent behavior at each step. These judgments can come from LLM-based evaluators, rule-based checks, human review, or (most often in production) a combination.
Feedback routing: directing the right signals to the right learning layer. A systematic hallucination pattern is a model-layer signal. A repeated failure in tool-call formatting is a harness-layer signal. A gap in the agent’s knowledge about a specific customer segment is a context-layer signal. Without evaluation that categorizes failures, you can’t route improvements to the right layer.
Verification: confirming that changes at any layer actually helped. After the harness gets updated, did the failure rate drop? After the context memory gets refined, did the relevant dimensions improve? Without verification, you’re making changes and hoping.
Harrison’s framework positions traces as the primitive that powers all learning, and he’s right that traces are foundational. But I’d go further: the real primitive is the evaluated trace, a trace with structured judgments about what was good, what was bad, and why.
Raw traces power observation. Evaluated traces power improvement.
Why runtime signals are the highest-quality learning data
Here’s where this gets practical. If evaluation is the cross-cutting layer, where do the best evaluation signals come from?
The typical answer is offline evaluation: run your agent through a test suite, score the results, improve, repeat. This matters and every serious team does it. But offline evaluation has a fundamental limitation. Your test suite is a model of production. It’s not production itself. The gap between what your test suite covers and what users actually do is where the worst failures hide.
Runtime evaluation, the kind that happens while the agent is serving real users, produces a different class of signal. When a guardrail fires in production, that’s not a synthetic scenario. That’s a real user, with real data, triggering a real failure mode that your test suite may never have anticipated.
This is where runtime guardrails become interesting not just as governance tools but as learning infrastructure. Every Deny and every Steer produces a structured evaluation signal: what policy was violated, at which step, with what input, and what the agent was trying to do. Over thousands of runs, these signals form a map of exactly where your agent needs to improve, and at which layer.
From theory to practice: what evaluation infrastructure looks like
I’ve been making the case that evaluation should be infrastructure, not a step. Let me show what that looks like when you build it.
At Galileo, we’ve built this evaluation layer across three components.
Agent Control generates the signals described above. These structured judgments from runtime governance are the raw material for everything downstream.
Signals handles pattern detection and diagnosis. This is where the “evaluated trace” concept becomes real. Signals doesn’t just process traces one batch at a time and forget. It maintains what we call institutional memory: a compressed representation of every pattern it has previously identified across your agent infrastructure. Each new analysis builds on all previous findings.
Why does this matter for continual learning? Because the most dangerous agent failures are the ones that emerge gradually over weeks. We’ve seen this in production: a customer service agent who slowly drifted away from compliance with the refund policy over a two-week period. Week one showed strict adherence. Week two started approving gray areas. Week three approved an explicitly prohibited case. Any single trace looked fine. The pattern was only visible across time, and only to a system that remembered what “normal” looked like three weeks ago.
Signals classifies failures by type and severity. A priority-10 signal about cross-customer data leakage routes to a different intervention than a priority-4 signal about unnecessary tool calls. The diagnosis determines whether you need a context update, a harness fix, or a model change.
The most important part of Signals is what happens after detection. When it identifies an unknown pattern, you can generate a new eval metric directly from that signal. Today’s unknown unknown becomes tomorrow’s monitored metric. Your evaluation suite evolves with your system rather than staying frozen at whatever you thought to test at launch. This is the eval engineering loop: observe, detect, codify, monitor.
MCP server closes the loop back to code. MCP integration brings Signals directly into your IDE, whether that’s Cursor, VS Code, or another MCP-compatible environment. You can prompt your coding agent: “Fetch the most recent signals and propose fixes for the top priority issues.” The agent gets the root cause analysis, the affected traces, and the suggested intervention, then proposes changes to your harness code or context instructions.
This connects directly to Harrison’s harness-layer learning. The Meta-Harness pattern he describes (run agent → evaluate → use coding agent to improve harness) is exactly right. The difference lies in the source of the evaluation signal. In his description, it comes from a test suite. Here, it comes from production evaluation infrastructure that has been accumulating institutional knowledge about your agent’s failure modes for weeks.
The three pieces together form a cycle:
Agent Control generates runtime evaluation signals → Signals analyzes them with institutional memory and diagnoses root causes → MCP brings the diagnosis into the IDE where coding agents propose fixes → the fixed agent deploys with updated Agent Control policies → the cycle continues.
Each rotation makes the agent more reliable.
The generalized loop
Abstracting from our specific tools, here’s the pattern:
Step 1: Observe. Collect traces from production.
Step 2: Evaluate. Run structured evaluations on those traces, not just pass/fail but multi-dimensional judgments. This is where most teams skip or use crude proxies.
Step 3: Diagnose. Classify failure patterns by learning layer. Model capability gap? Harness configuration issue? Missing context instruction?
Step 4: Intervene. Make a targeted change at the right layer. Without Steps 2 and 3, interventions are guesses.
Step 5: Verify. Evaluate again. Did the failure pattern improve? Did anything else regress?
Step 6: Repeat. The evaluation layer runs forever, providing the feedback signal that makes every other layer’s learning reliable.
Skip Step 2 and Step 5, and you have a system that changes over time but has no way to confirm it’s improving. You have continual drift.
Why this matters now
The conversation about continual learning for agents is picking up because agents are moving from demos to production. Demo agents don’t need to learn. They’re rebuilt from scratch every few weeks. Production agents need to improve without breaking, continuously, across thousands of interactions with real users.
The teams that will do this well won’t be the ones with the most traces. They’ll be the ones with the best evaluation infrastructure. Because traces without evaluation are just logs. And optimization without measurement is just hope.
I’m writing about eval engineering as a discipline, the practice of systematically measuring and improving AI system quality. If you’re building agents for production and thinking about reliability, I’d like to hear what evaluation patterns are working for your team.