


Transfer Learning In NLP - Part 2
A lot has changed

Not for the faint-hearted!

Photo by David Boca on Unsplash
This is a follow up to my inception post Transfer Learning In NLP. In case you are just getting started in NLP, have a look at it first.
A lot has happened after Oct 2018 — when BERT was released.
Do you know BERT’s masked language modelling is old school?
Do you know attention doesn’t need to be quadratic in time?
Do you know you can steal Google’s model?
Some of the smartest people of our generation have been working intensely and churning out a lot! NLP is probably the sexiest field to be in right now 😋
NLProc has come a long way.
We need another summary!!!
These 20 questions will test how updated you are with the current state of NLP and make you ready for any technical discussion.
After all, you are only as good as the number of jargons you know 😆
What is the current state of Pre-trained models(PTM)?
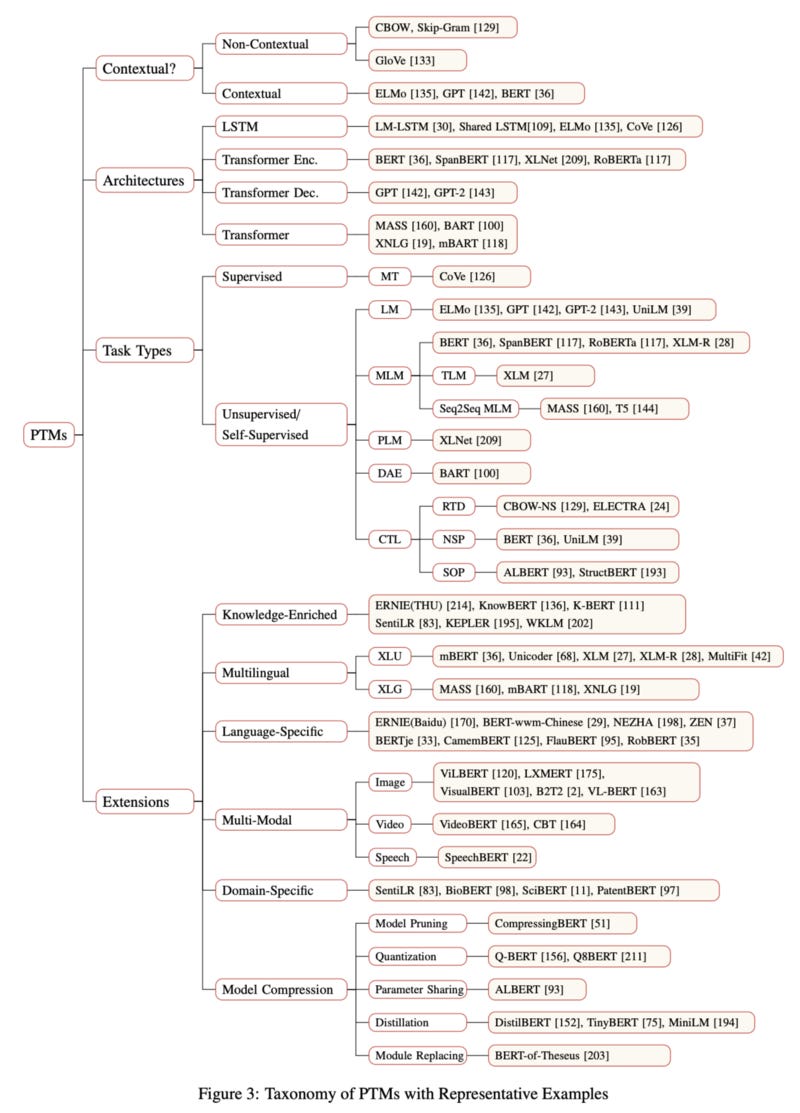
https://arxiv.org/pdf/2003.08271.pdf
Which tasks are used for training PTMs?
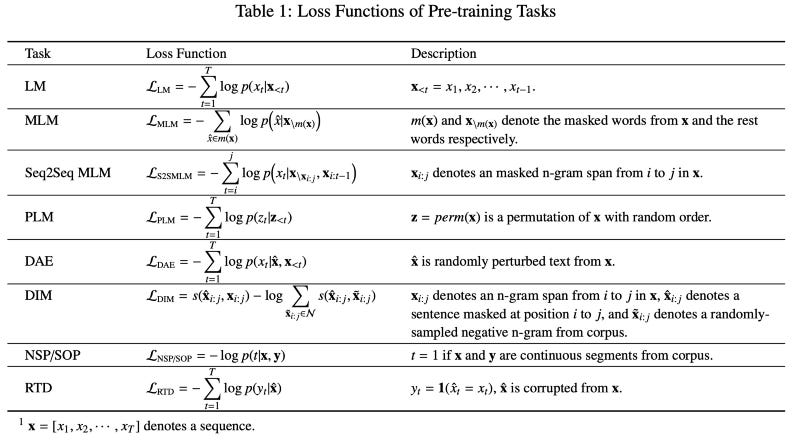
https://arxiv.org/pdf/2003.08271.pdf
What is the current state of PTMs on GLUE?
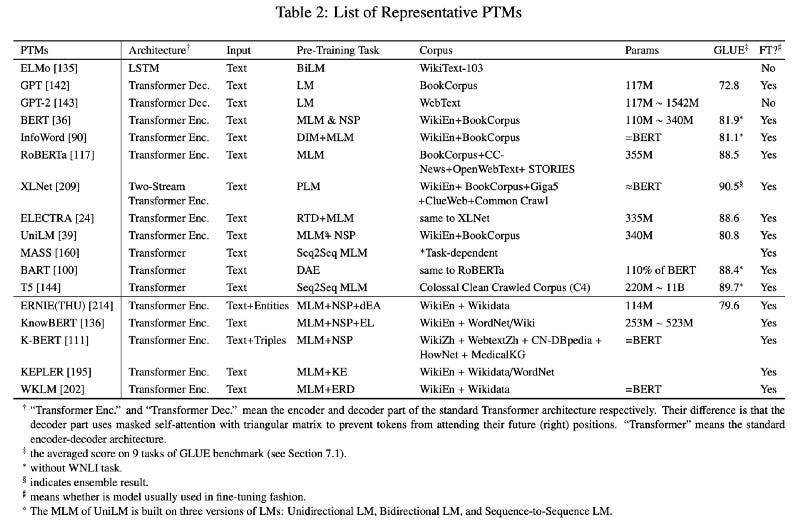
https://arxiv.org/pdf/2003.08271.pdf
Does more data always lead to better language model?
T5 paper says no. Quality matter more than quantity.

https://arxiv.org/pdf/1910.10683.pdf
What tokenisation method seems best for training language models?
This paper says that a new method Unigram LM is better than BPE and WordPiece.
Which task is best for training a language model?
The current best approach is by ELECTRA → Replacing an input token with the help of a generator and then using a discriminator to predict which token was corrupted.

https://arxiv.org/pdf/2003.10555.pdf
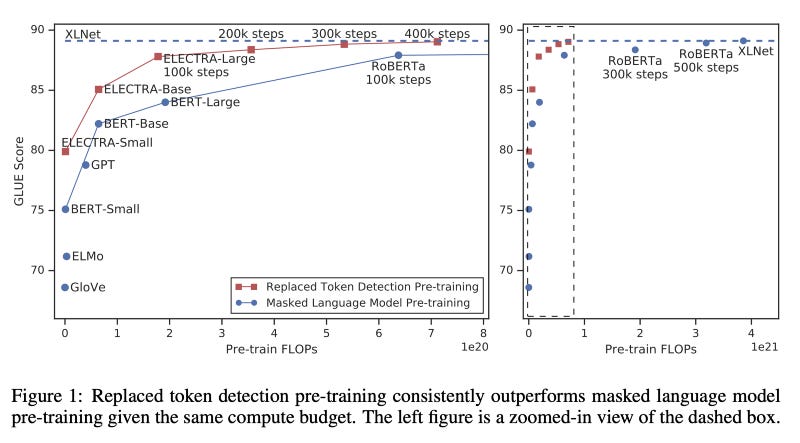
https://arxiv.org/pdf/2003.10555.pdf
Also T5 paper says dropping a span of 3 is good.

https://arxiv.org/pdf/1910.10683.pdf
Is gradual unfreezing needed for task training of transformer?
T5 paper says no.
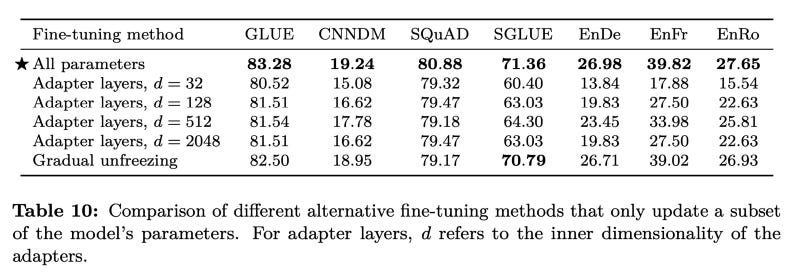
https://arxiv.org/pdf/1910.10683.pdf
What would you change to get a better language model if you have a fixed budget of training?
T5 paper suggests increasing both size and training steps.
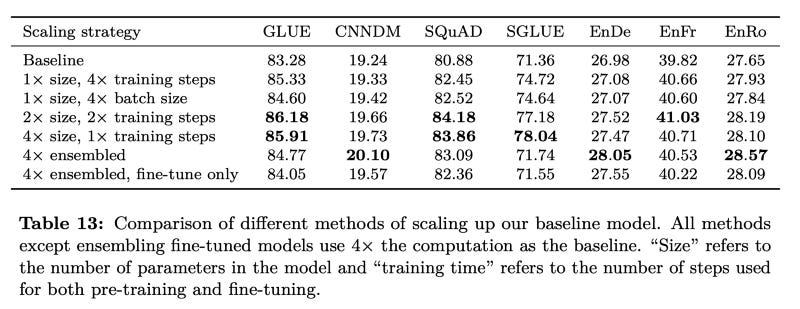
https://arxiv.org/pdf/1910.10683.pdf
Which model would you use if your sequence is longer than 512 tokens?
Transformer-XL or Longformer
How does the processing time of transformer scale with sequence length?
Quadratic
How can we bring down the processing time of transformers for long documents since it is quadratic in nature with sequence length?
Longformer uses an attention mechanism that scales linearly with sequence length.
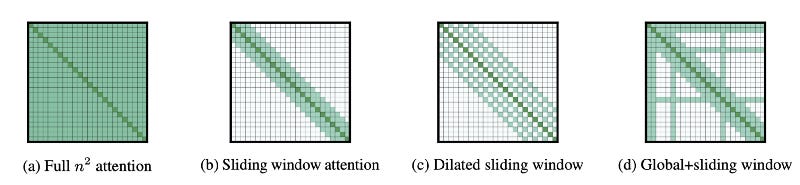
https://arxiv.org/pdf/2004.05150.pdf
Longformer can be really good for encoding long documents for semantic search. Below table shows the work done till now.
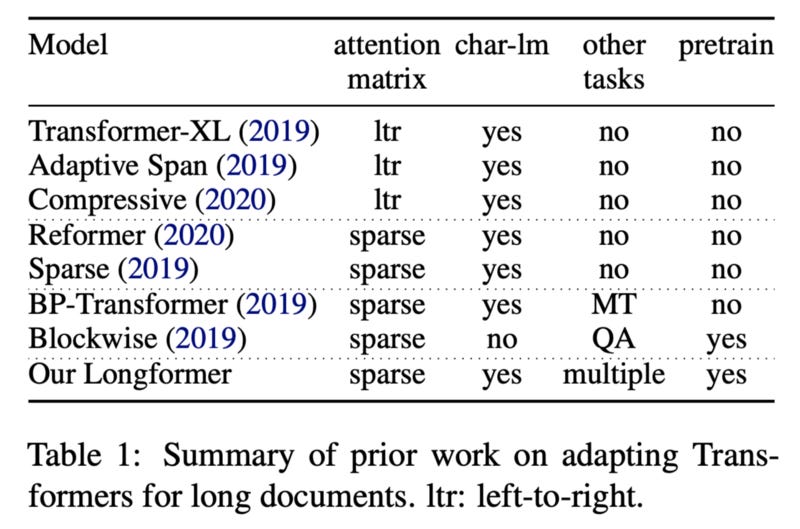
https://arxiv.org/pdf/2004.05150.pdf
Does BERT perform great because of its attention layer?
Paper Attention is not Explanation argues that attention is not properly correlated to outputs and hence we cannot say the model performs better because of attention mechanism.
Will the performance of BERT fall drastically if we turned off a head?
No — As per paper Revealing the Dark Secrets of BERT
Will the performance of BERT fall drastically if we turned off a layer?
No — As per paper Revealing the Dark Secrets of BERT
Will the performance of BERT fall drastically if we randomly initialised it?
No — As per paper Revealing the Dark Secrets of BERT
Do we really need model compression?
Maybe not! Notes from this amazing article.
“Model compression techniques give us a hint about how to train appropriately-parameterized models by elucidating the types of solutions over-parameterized models tend to converge to. There are many types of model compression, and each one exploits a different type of “simplicity” that tends to be found in trained neural networks:”
Many weights are close to zero (Pruning)
Weight matrices are low rank (Weight Factorization)
Weights can be represented with only a few bits (Quantization)
Layers typically learn similar functions (Weight Sharing)
Can we steal a model if exposed as API?
Yes, we can → explained in this mind-blowing post.
What is the current state of distillation?
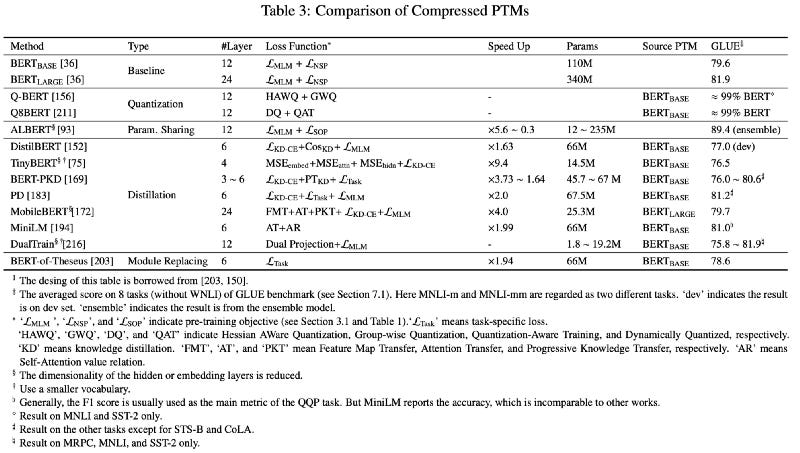
https://arxiv.org/pdf/2003.08271.pdf
Does a bigger transformer model train faster or a smaller?
Bigger model as per this article.
What are the applications of student-teacher framework?
Knowledge distillation for making smaller models
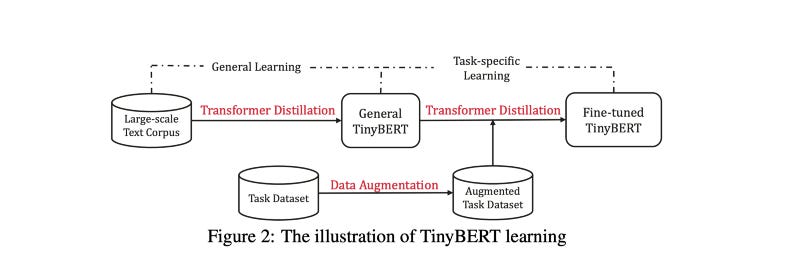
https://arxiv.org/pdf/1909.10351.pdf
Generate similar sentence embeddings for different languages
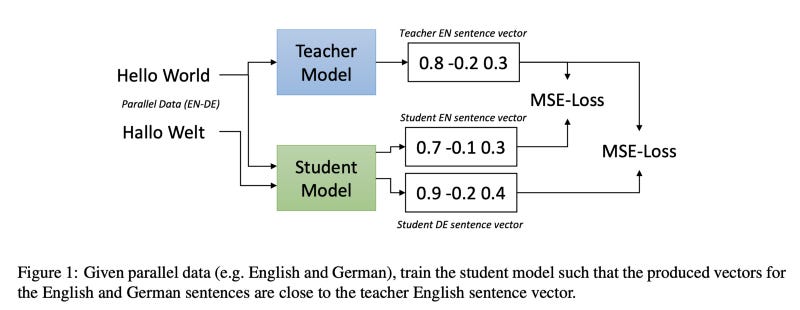
https://arxiv.org/pdf/2004.09813v1.pdf
How to design models? Which are the most important parameters?
This is a very difficult question!
All this is explained in Scaling Laws for Neural Language Models which gives us the correlations between
test loss Vs compute
test loss Vs dataset size
test loss Vs parameters
To design and train a model, first decide the architecture. Then get its no. of parameters. From this, you can calculate the loss. Then select the data size and compute required.
See the scaling equations in the graph.

Scaling Laws for Neural Language Models
Finallyyy…
I hope you got to learn as much as I did going through these questions. To become better NLP engineers, we need to have a deeper understanding of transfer learning which is evolving very quickly.
I believe these ideas will keep you busy for weeks 😃😬😎
Modern NLP
All the latest techniques in NLP — Natural Language Processingmedium.com