


Generalization In NLP
The elephant in the room

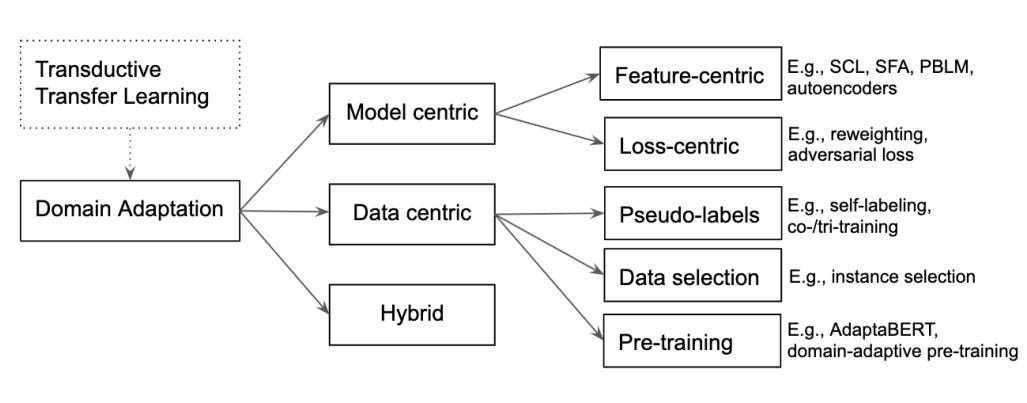
Out of domain(OOD) generalization is a serious problem in NLP.
No matter what we train for, our models need to be good at handling/detecting out of domain data. Our model can always surprise us as the world keeps changing as people keep changing. One way to circumvent it is by periodic retraining but it can be costly and creating new tagged data is just trouble.
Hence it is important to understand this problem and find ways to mitigate it.
Which model architectures are more robust to OOD?
A. Transformers
Why transformers are more robust?
Is it pretraining?
Is it pretraining with large data?
Is it the self-supervised pretraining?
Is it pretraining with large diverse data?
Are bigger transformer models more robust to OOD?
Which training methods lead to a more robust model?
How can we test for OOD before the deployment?
These papers answer some of these questions
Pretrained Transformers Improve Out-of-Distribution Robustness
Our Evaluation Metric Needs an Update to Encourage Generalization